

Remote Dictionary Server

Redis 十大数据类型
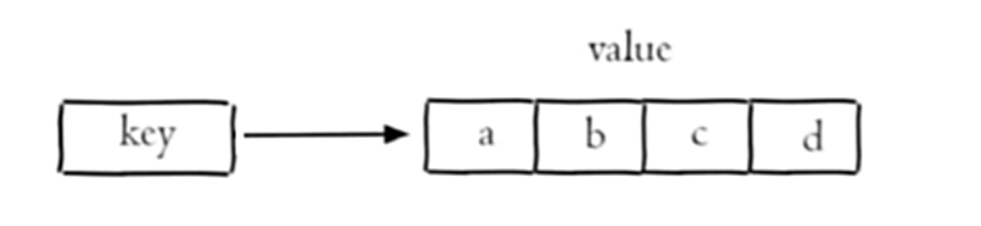
Key
命令不区分大小写
Key 区分大小写
-
查看所有 key
keys * -
exists key -
type key -
del key -
unlink key非阻塞删除,仅仅将 keys 从keyspace元数据中删除,真正的删除会在后续异步中操作。
del key是原子的删除,只有删除成功了才会返回删除结果,如果是删除大 key 用 del 会将后面的操作都阻塞,而 unlink key 不会阻塞,它会在后台异步删除数据 -
ttl key查看还有多少秒过期,-1表示永不过期,-2表示已过期 -
expire key为给定的key设置过期时间 -
move key dbindex[0-15]将当前数据库的key移动到给定的数据库DB当中 -
select dbindex切换数据库【0-15】,默认为0 -
dbsize -
flushdb [ASYNC/SYNC] -
flushall -
help @类型,help @hash
keys pattern keys * keys set*
exists key
type key
del key

字符串 String
string 是 redis 最基本的类型,一个 key 对应 一个 value
string 类型是 二进制安全 的,意思是 redis 的 string 可以包含任何数据,比如 jpg 图片或者序列化的对象。
string 类型是 Redis 最基本的数据类型,一个 redis 中字符串 value 最多可以是 512M
SET key valueGet keySETEX key seconds valueSETNX key valueSet if not exists

列表 (list)
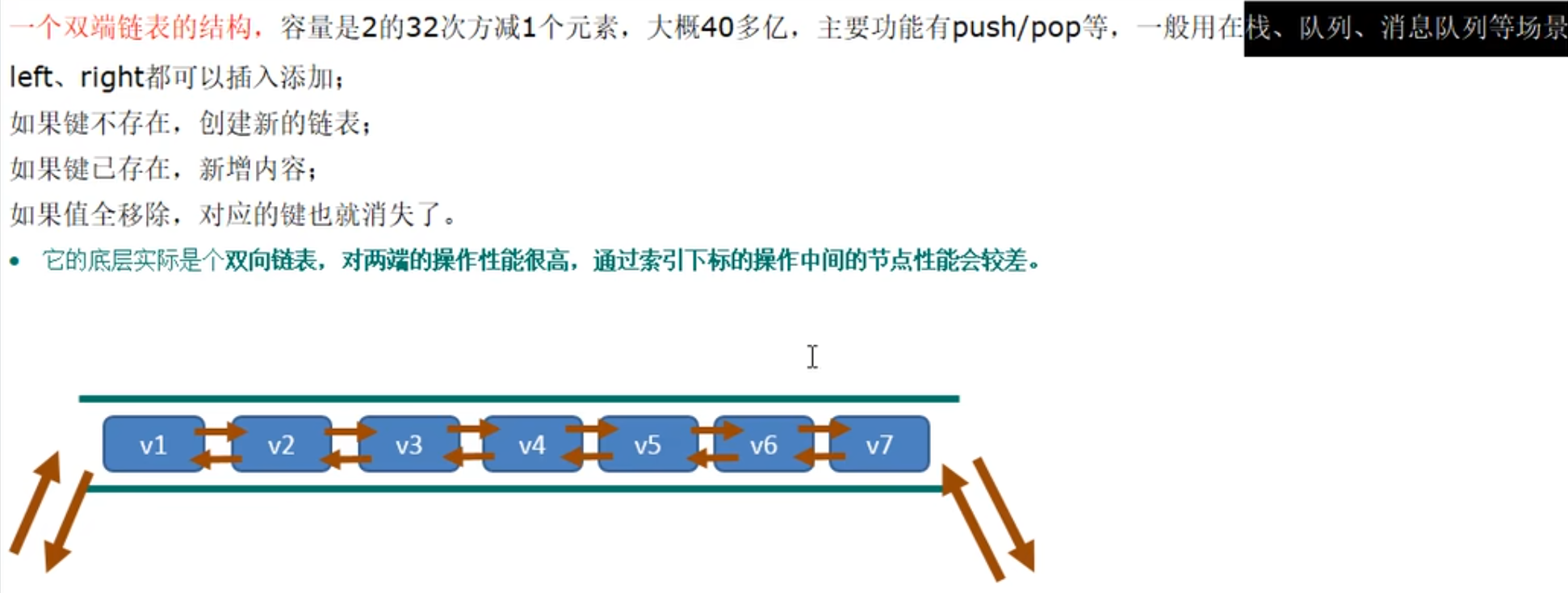
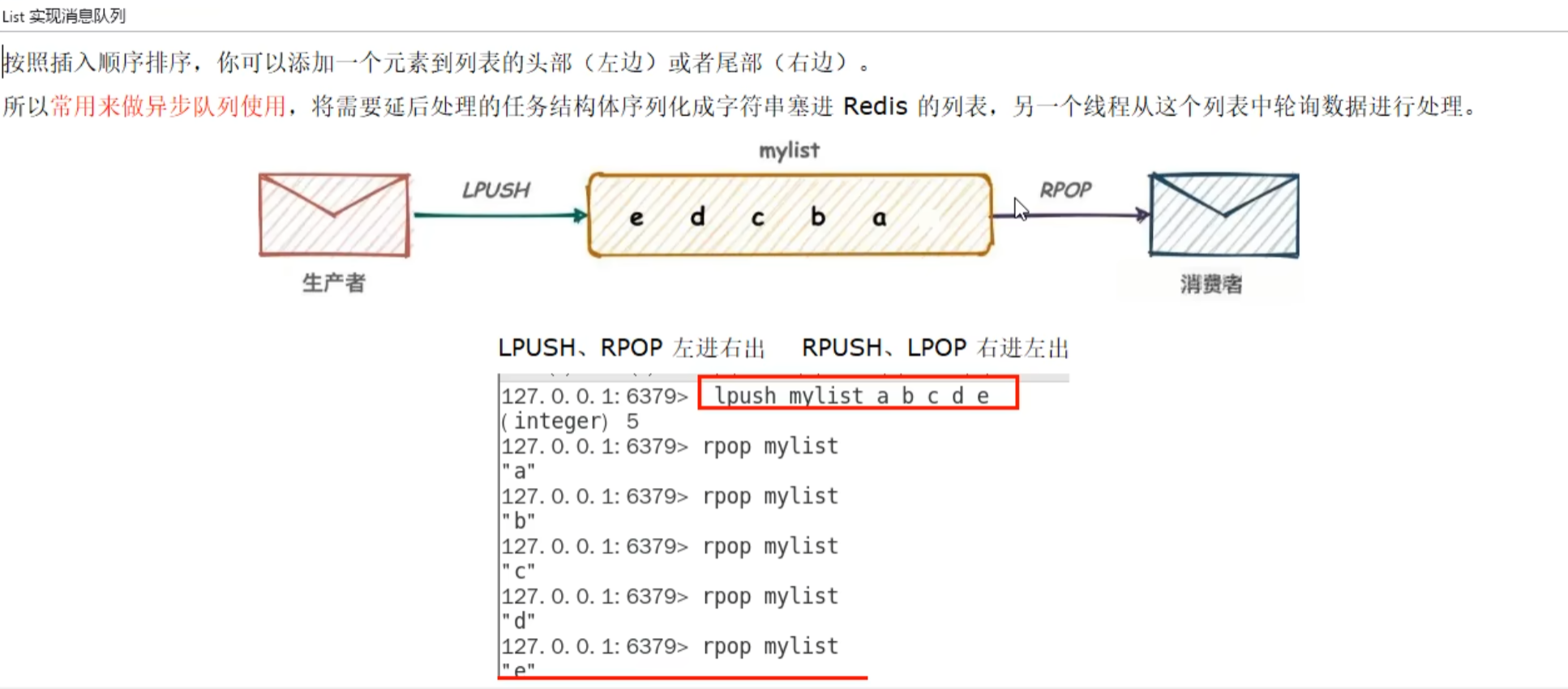
Redis 列表是简单的字符串列表,按照插入顺序排序。你可以添加一个元素到列表的头部(左边)或者尾部(右边)
它的底层实际是个双端链表,最多可以包含 2^32-1 个元素 (4294967295,每个列表超过 40 亿个元素)
简单的字符串列表,按照插入顺序排序

lpush key value1 value2 value3lrange key start stop0 代表头部,-1 代表尾部rpop keyllen keylindex key indexllen keylrem key number valuenumber=0 代表全部ltrim key index1 index2删除从索引index1到索引index2的值rpoplpush key1 key2将 key1 最后一个数据弹到 key2
lset key index value替换linsert before value1 value2/aftervalue1 value2before 在 value 1 前插入 value 2





最后插入的在第一位
哈希 (hash)
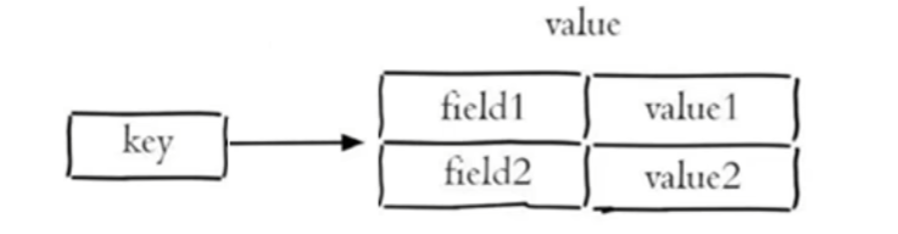
一个 String 类型的 field 和 value 的映射表,hash 特别适合存储 对象
Redis hash 是一个 string 类型 field (字段)和 value (值)的映射表, hash 特别适合用于存储对象。
Redis 中每个 hash 可以存储 2^32-1 键值对 (40 多亿)
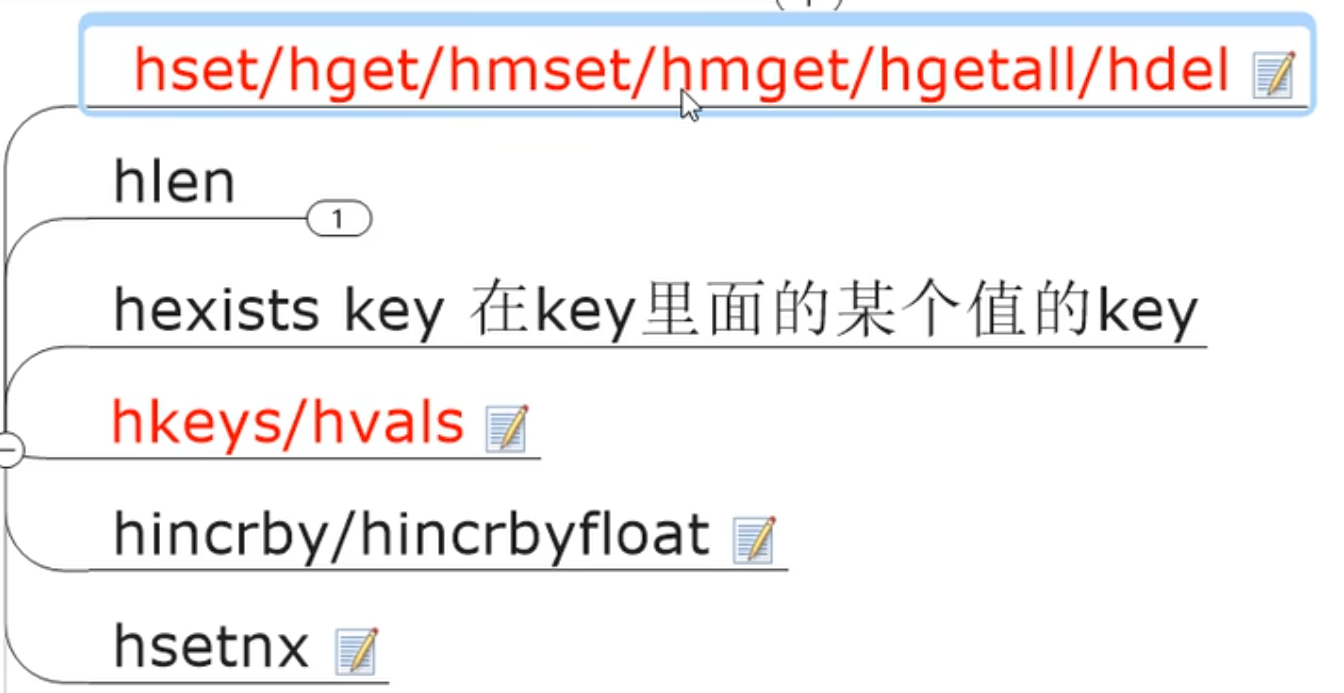
HSET key field valueHGET key fieldHDEL key fieldHKEYS keyHVALS keyhlen keyhexists keyhkeys/hvalshincrby/hincrbyfloathsetnx

集合 (set)
单值多 value, 无重复,无序无重复, list 是有序有重复
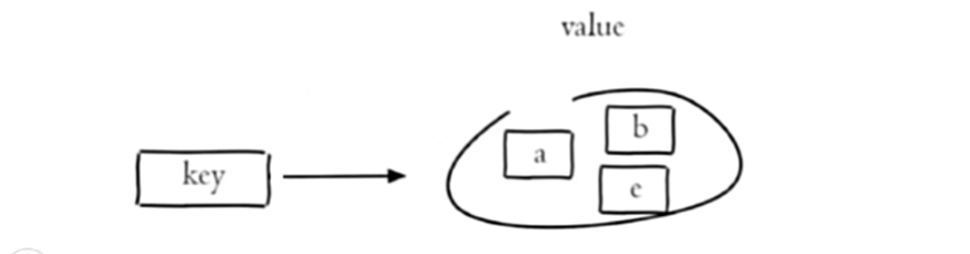

String 类型的无序集合,集合成员是唯一的,集合中 不能重复 的数据
Redis 的 Set 是 String 类型的无序集合。集合成员是唯一的,这就意味着集合中不能出现重复的数据,集合对象的编码可以是 intset 或者 hashtable
Redis 中 Set 集合是通过哈希表实现的,所以添加,删除,查找的复杂度都是 O(1)
集合中最大的成员数为 2^32-1 (4294967295,每个集合可存储 40 多亿个成员)


kepptll默认改后的ttl会变成-1, 需要指定不变
mset/mget 批量
getrange/setrange
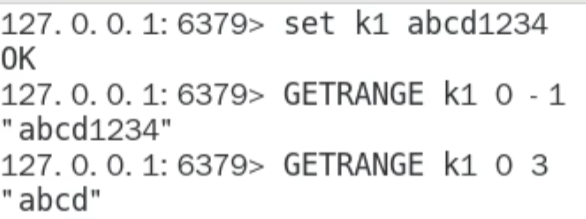

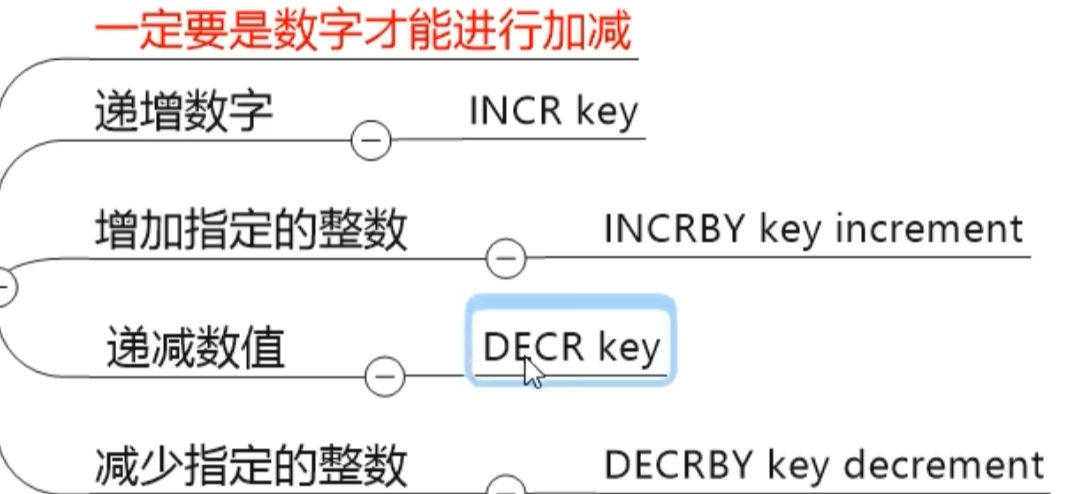
INCR
INCRBY
DECR
DECRBY
STRLEN k1 xxx (String Length)
APPEND key value

-
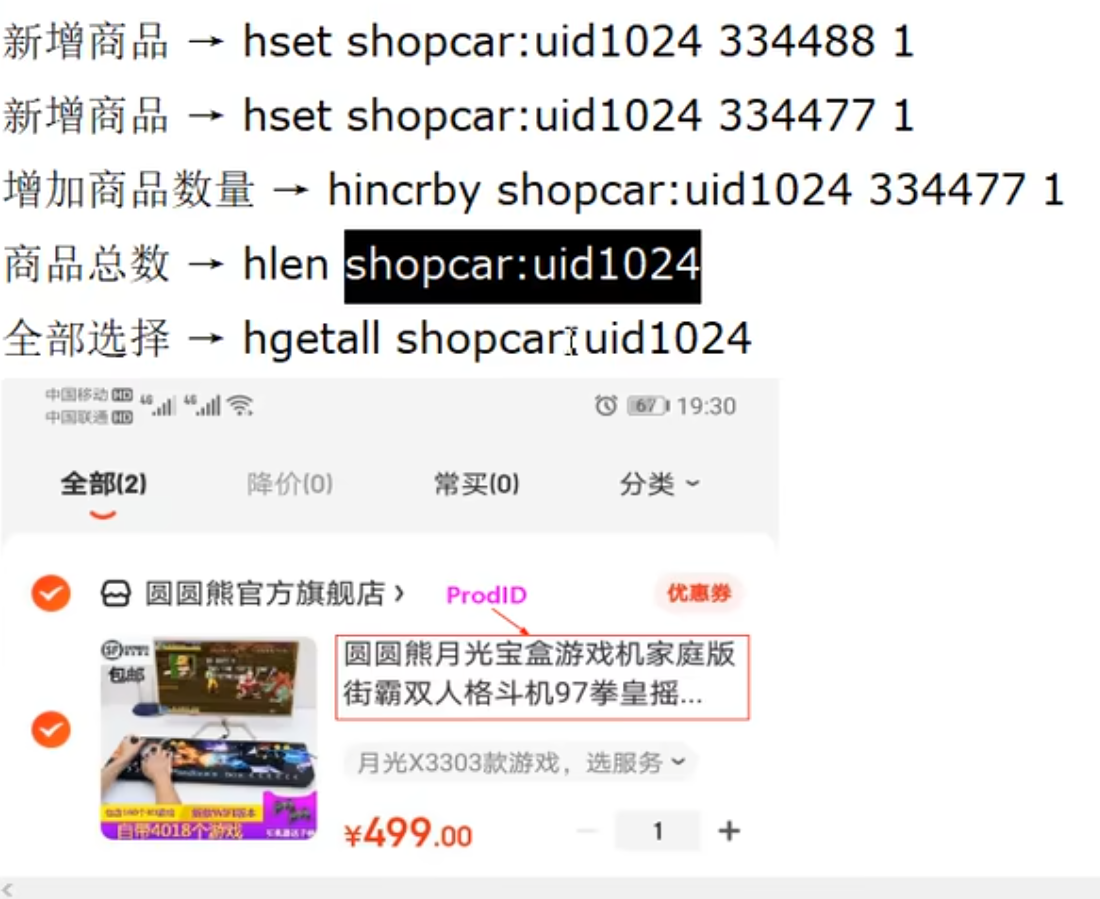
sadd key nember1 number2 number3添加的有重复时会自动去重 -
smembers key遍历 -
scard key个数 -
srem key member1 member2 member3删除 -
srandmember key [数字]从 key 中随机展示[数字]个的元素,元素不删除 -
spop key[数字]从集合中随机弹出一个元素,弹一个删除一个 -
smove key1 key2 value将 key1 中的 value 迁移给 key2
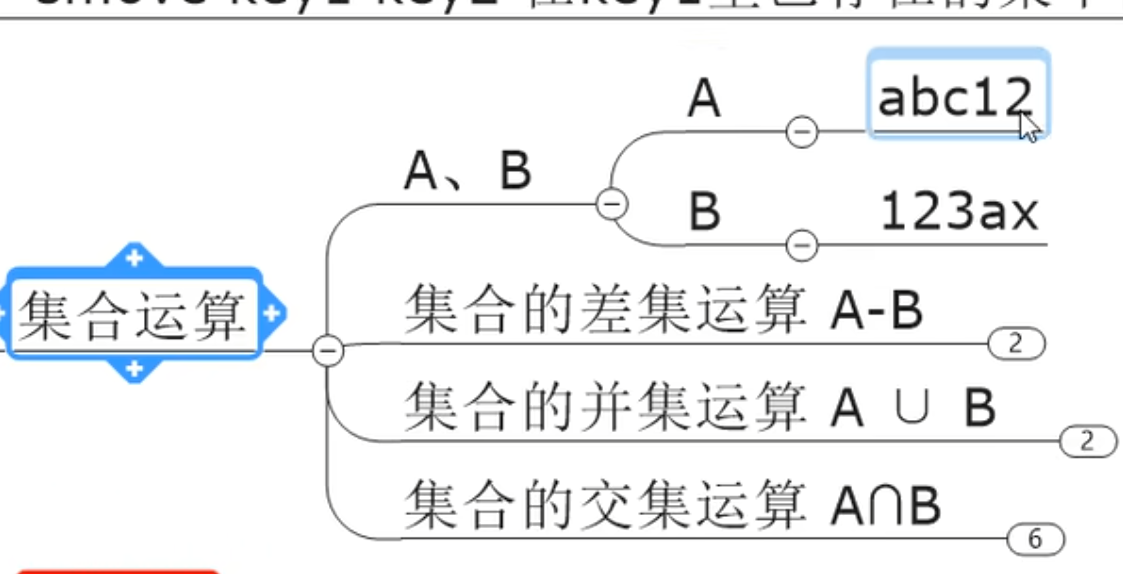
-
sdiff key1 key2:key 1-key 2的结果 -
sinter key1 key2 key3交集 -
sintercard numkeys key [key...] [LIMIT limit]也是交集,返回个数

-
sunion key1 key2 key3并集


全部成功才有效
有序集合 (ZSET)
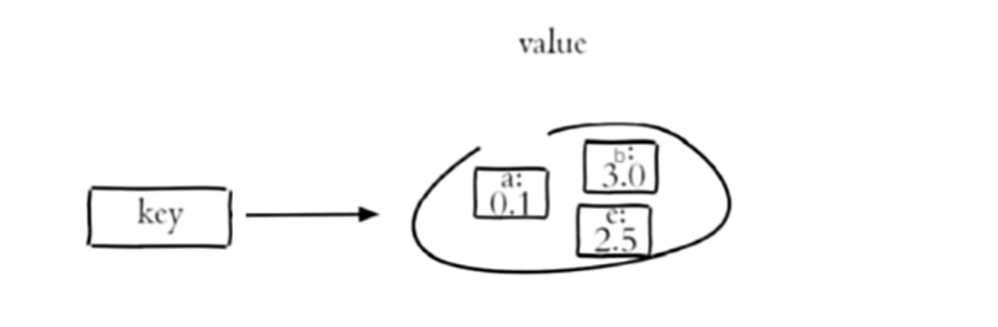
String 类型元素的集合,且不允许有重复成员,每个元素都会关联一个 double 类型的分数,通过分数进行排序
zadd key 分1 名1 分2 名2 分3 名3zscore key member获取元素分数zCARD key获取集合中元素的数量zrangen key start stop [withscores]zincrby key increment memberzrem key member [memeber ...]删除zmpop number key min count 1zrank key values/zrevrank key values获取下标值/逆序或者下标值


地理空间 (GEO)
乱码 : 使用中文连接 reids 时候要加 --raw
Redis GEO 主要用于存储地理位置信息,并对存储的信息进行操作
(经度,维度)
添加 地理位置的坐标。
获取 地理位置的坐标。
计算 两个位置之间的距离。
根据 用户给定的经纬度坐标来获取指定范围内的地址位置集合
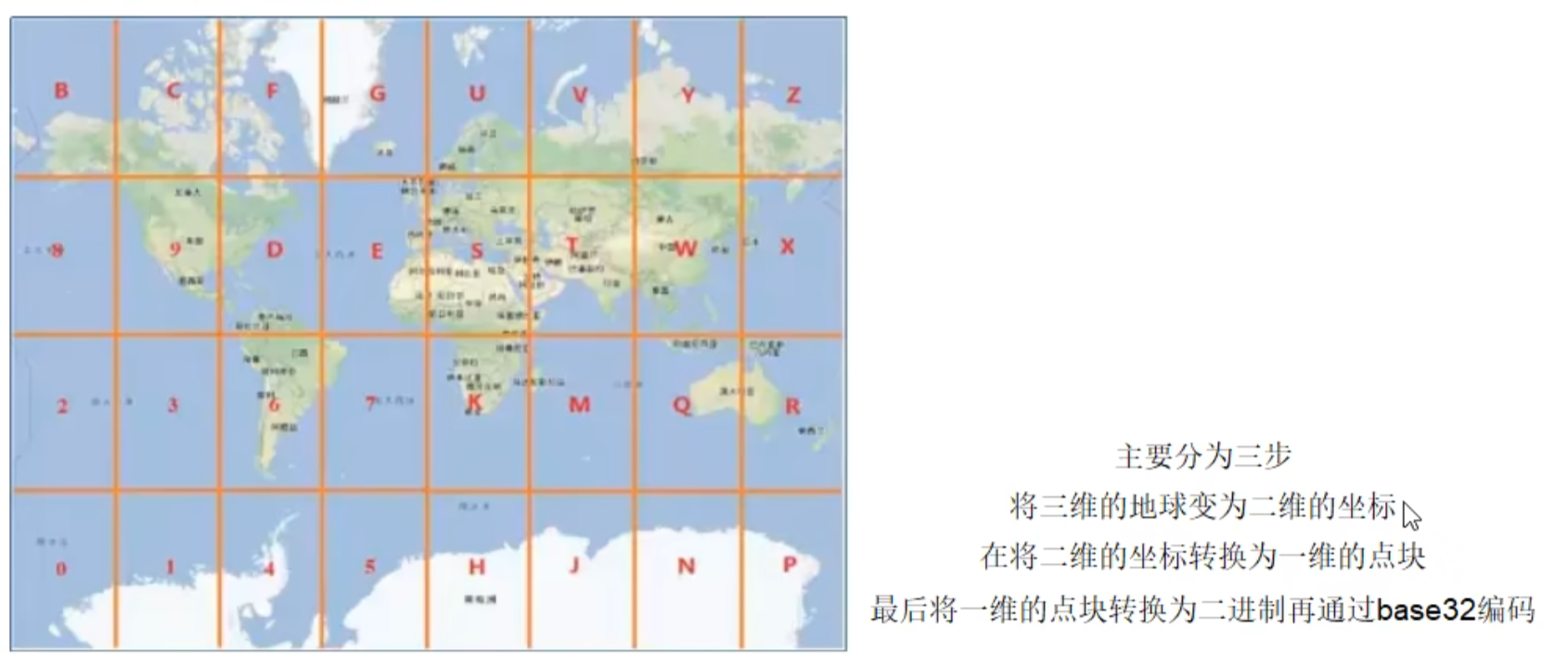
-
geoadd key 经度 维度 name
GEOADD city 116.403963 39.915119 "天安门" 116.403414 39.924091 "故宫" 116.024067 40.362639 "长城" -
geopos返回经纬度

-
geohash返回坐标的geohash表示
生成base32的编码值,代表了坐标

-
geodist key name1 name2 [m|km|ft|mi]自动计算两个地方相距

-
georadius以给定的经纬度为中心,返回键包含的位置元素中,与中心的距离不超过给定最大距离的所有位置元素

-
georadiusbymember

redis 基数统计(HyperLogLog)
储存数据个数,不存储实际内容
HyperLogLog 是用来做 基数统计 的算法,具有 去重复统计 功能,是 String 类型
优点 : 输入元素的数量或者体积非常非常大时,计算基数所需要的空间总是固定且是很小的。
HyperLogLog是一种概率算法,储存的是数据的个数
在Redis里面,每个HyperLogLog键只需要花费12KB内存,就可以计算接近2^64个不同元素的基数。这和计算基数时,元素越多耗费内存就越多的集合形成鲜明对比。
但是,因为HyperLogLog只会根据输入元素来计算基数,而不会存储输入元素本身,所以HyperLogLog不能像集合那样,返回输入的各个元素。
统计大致多少人访问过一个页面,IP 同一个只代表一个,去重复统计独立访客


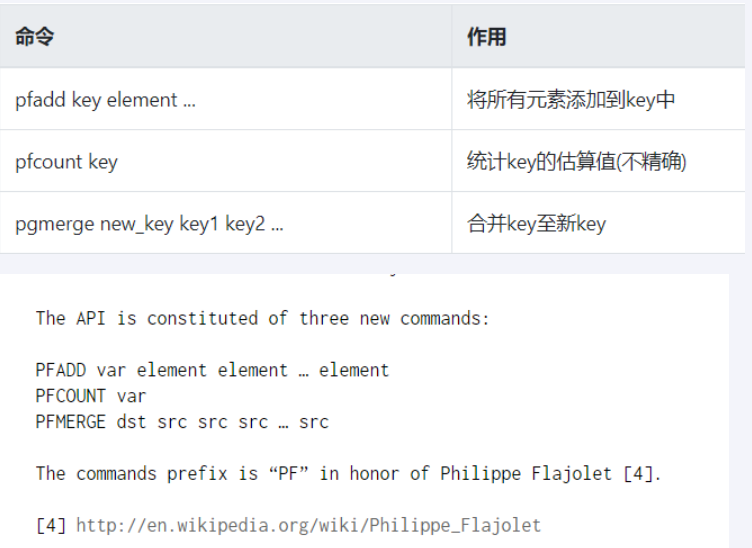
pfadd key value1 value2 value3pfcount keypfmerge key key1 key2合并 key1 ,key 2 ,并不会存储具体的值,只会告诉你数量
一句话:去重脱水后的真实数据

redis 位图(bitmap)
由 0 和 1 状态表现的二进制位的 bit 数组,相当于 string 的子类,类型还是string

是否登陆过,是否点过,打卡上下班,签到统计
使用 mysql 的数据量过大
setbit key 位置 值值只能 0 或 1getbit key 位置strlen统计字节占用多少, 8 位一个 bitmap
setbit k1 1 1setbit k1 7 1占用一个字节
setbit k1 1 1setbit k1 8 1占用两个字节bitcount key统计



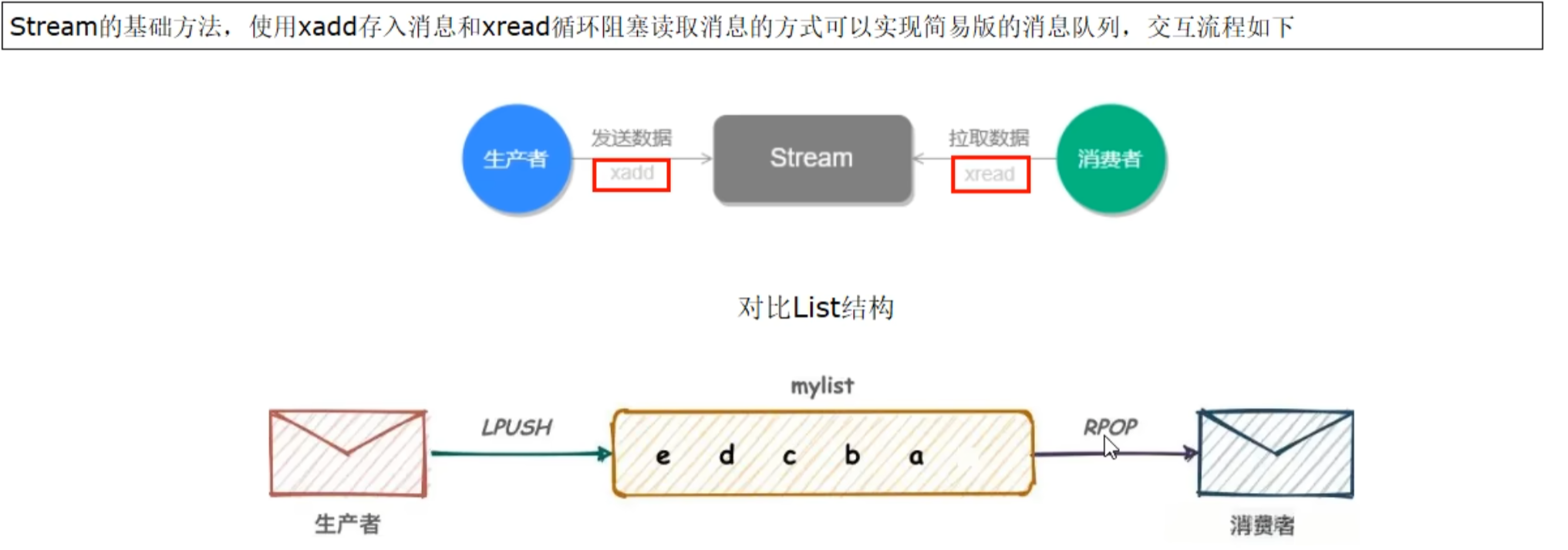
redis 流(Stream)
Redis Stream 是 Redis5.0版本新增加的数据结构。
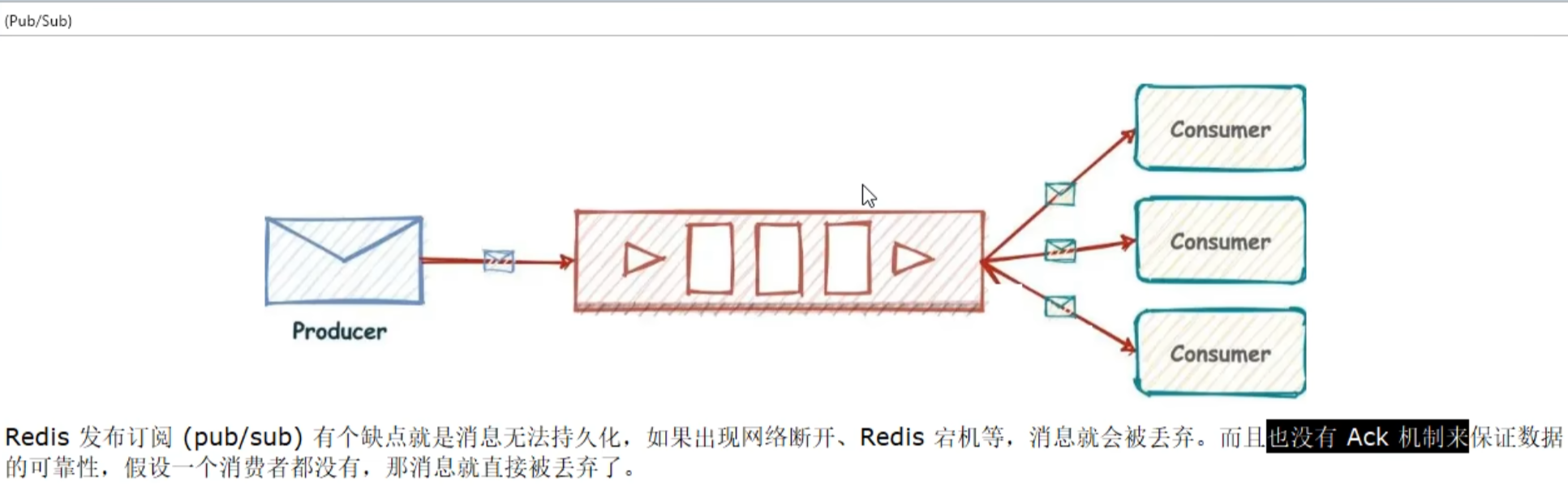
Redis Stream主要用于消息队列(MQ,Message Queue),Redis本身就是一个Redis发布订阅(pub/sub)来实现消息队列的功能,但它有个缺点就是消息无法持久化,如果出现网络断开、Redis宕机等,消息就会被丢弃。
简单来说发布订阅(pub/sub)可以分发消息,但无法记录历史消息。
而Redis Stream提供了消息的持久化和主备复制功能,可以让任何客户端访问任何时刻的数据,并且能记住每一个客户端的访问位置,还能保证消息不丢失。
5.0 之前

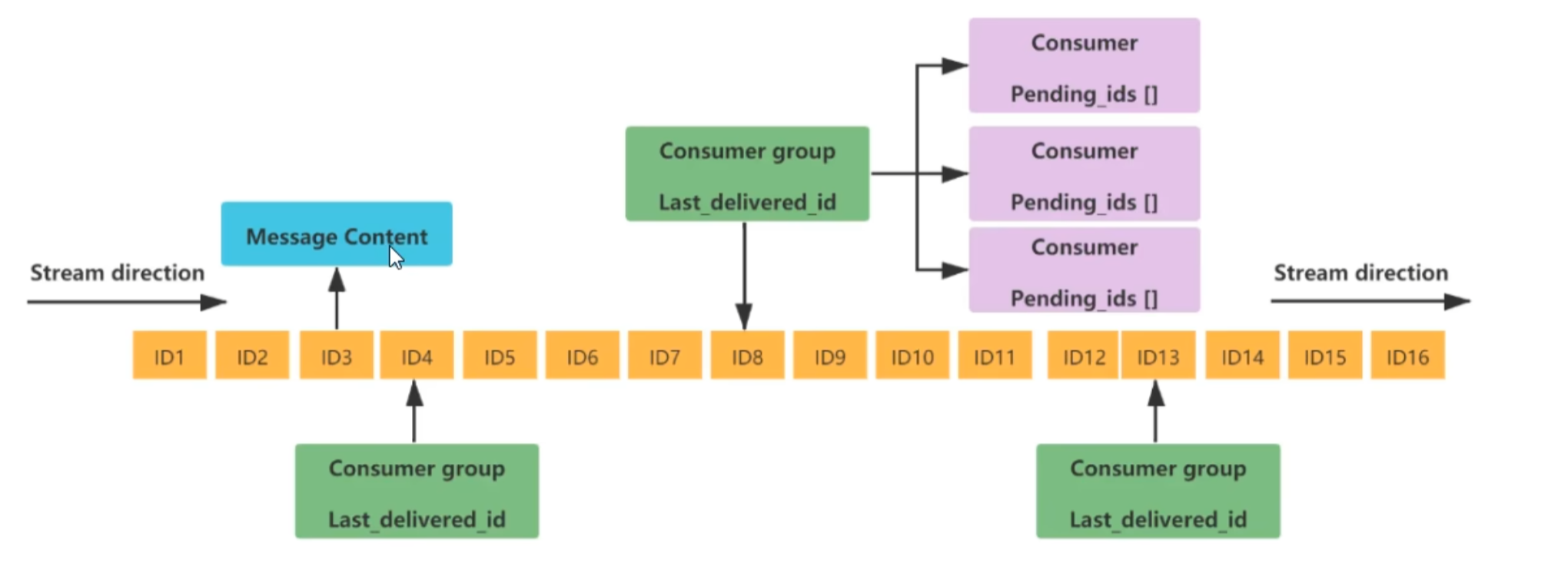

队列相关指令
队列: 即产生的一列 IDx
队列相关指令
xadd 队列名 * key1 value1 key2 value2
消息 id 必须比上一个大,*用于让系统自动生成 id, 会生成消息 ID



xrange mstream - +


-
xdel key ID -
xlen key - + -
xtrim key maxlen number最大的数量,前面的会被截掉

-
xread mstream - +

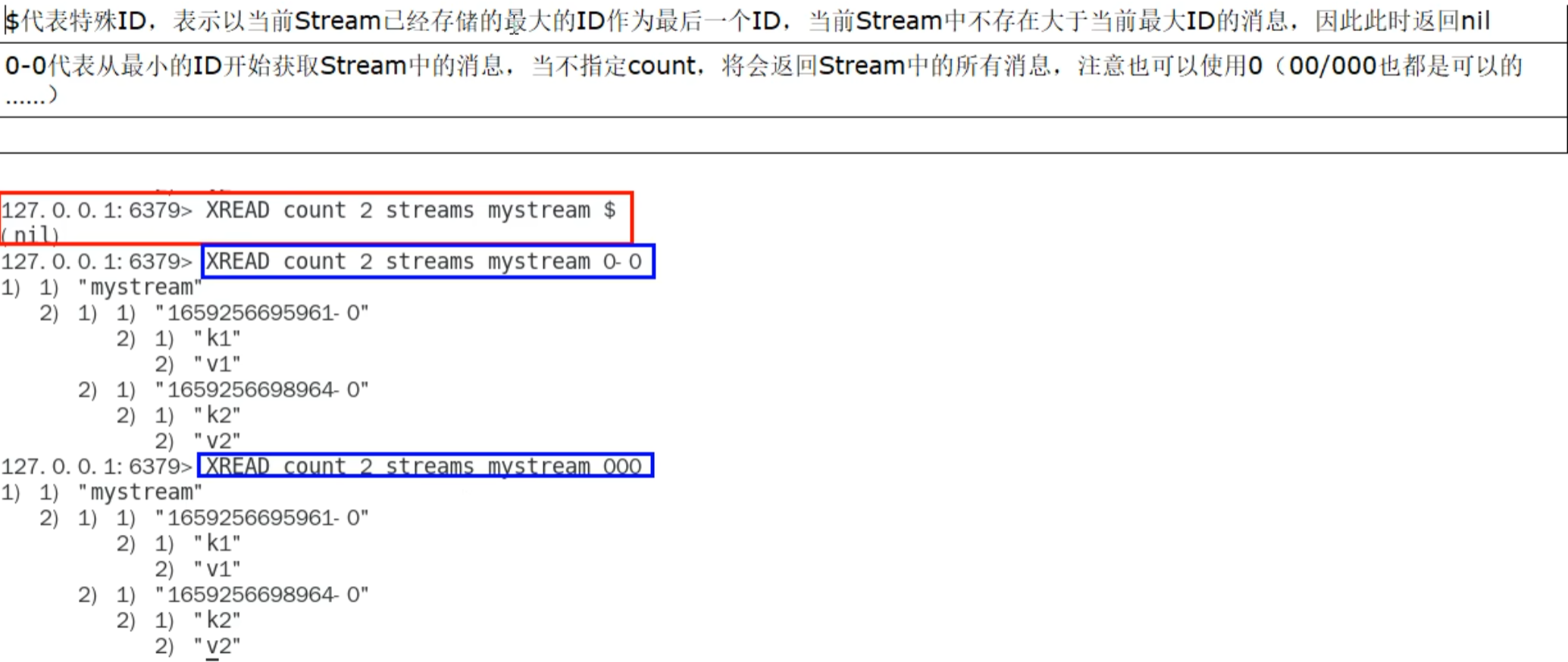
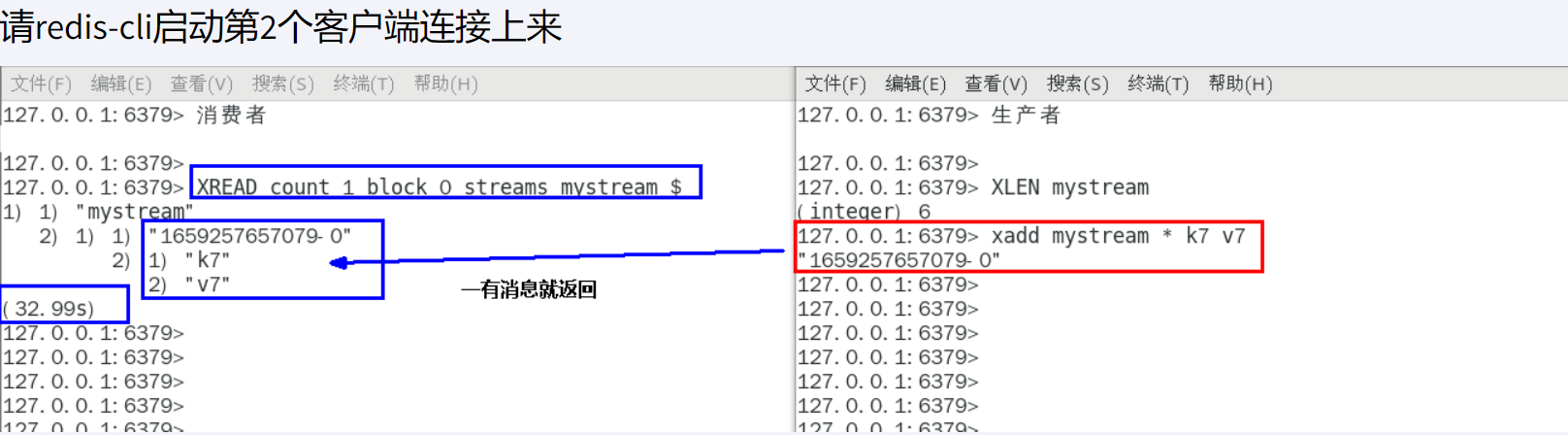
阻塞有最大的而才会返回,会告诉你等了多久
消费相关指令

-
xgroup 队列名 组名

-
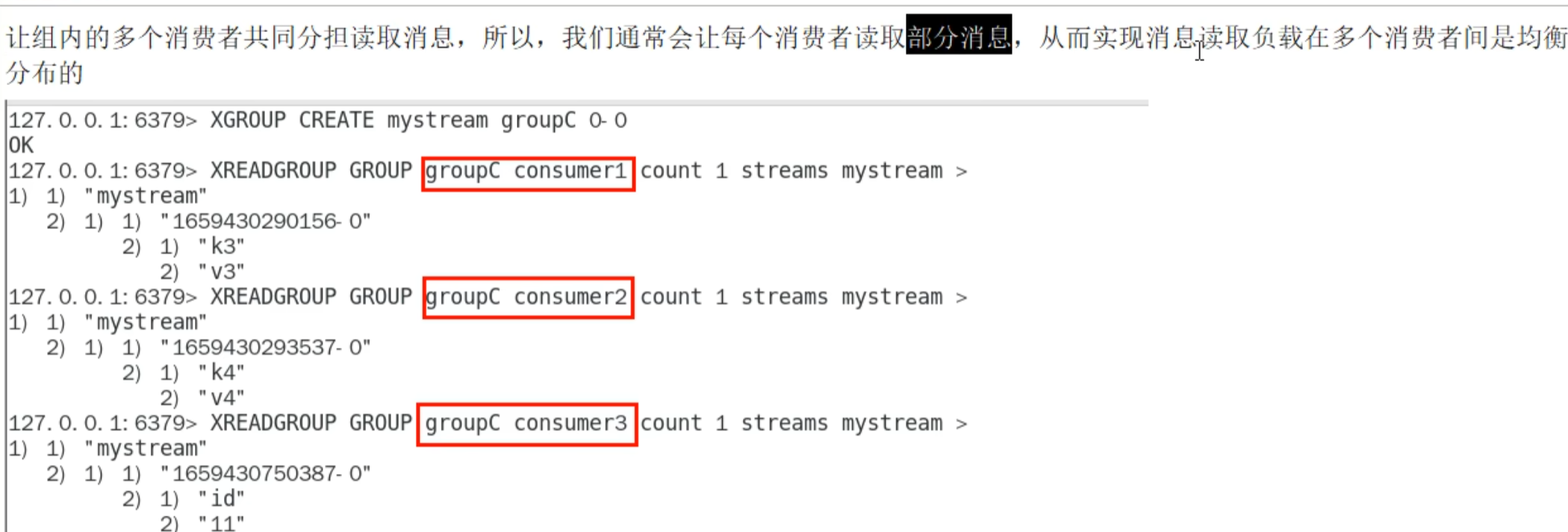
XREADGROUP GROUP 组名 消费名 STREAMS 队列名
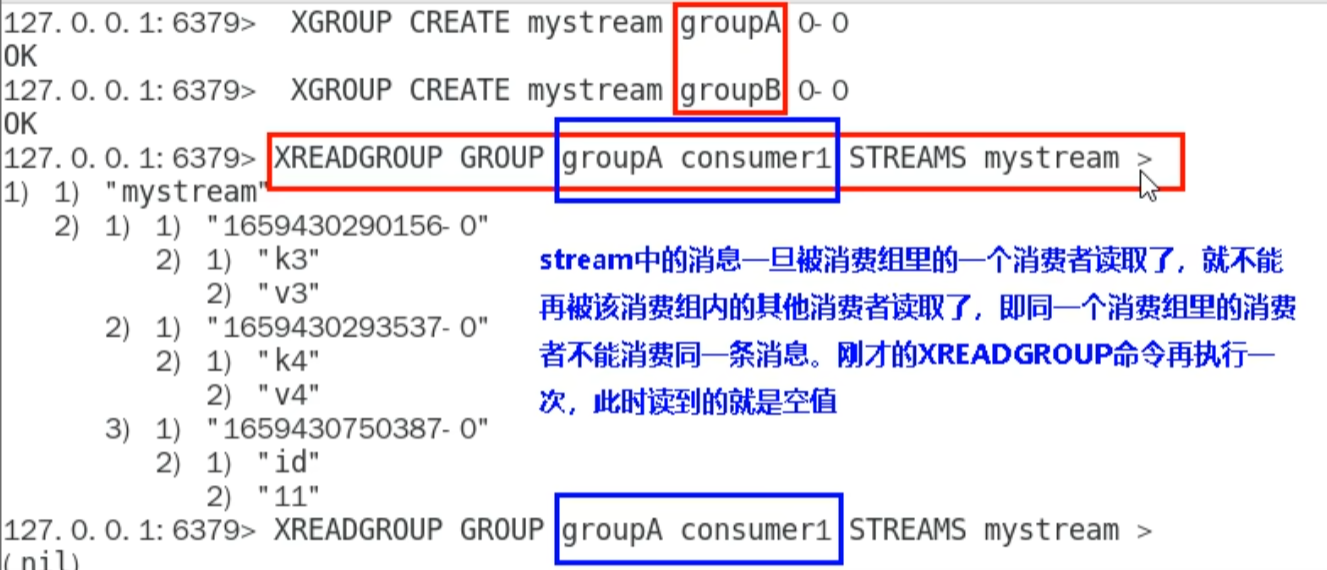
因为游标已经从头走到尾了,即使同组也不能读
但是不同组可以读

xpending 队列名 组名查询每个消费组内所有消费者

xpending 队列名 组名 - + count 消费者查看某个消费者读取了哪些数据

签收后再查读取过的数据会只剩没有签收的
xinfo stream 队列名

redis 位域(bitfield)(了解)
将 redis 字符串看作一个由二进制组成的数组,并能对变长位宽和任意没有字节对其的指定整形位域进行寻址和修改
通过 bitfield 命令可以一次性操作多个比特位域(指的是连续的多个比特位),它会执行一系列操作并返回一个响应数组,这个数组中的元素对应参数列表中的相应的执行结果。
说白了就是通过 bitfield 命令我们可以一次性对多个比特位域进行操作。



位域修改 ,溢出控制
相当于可以改字节码


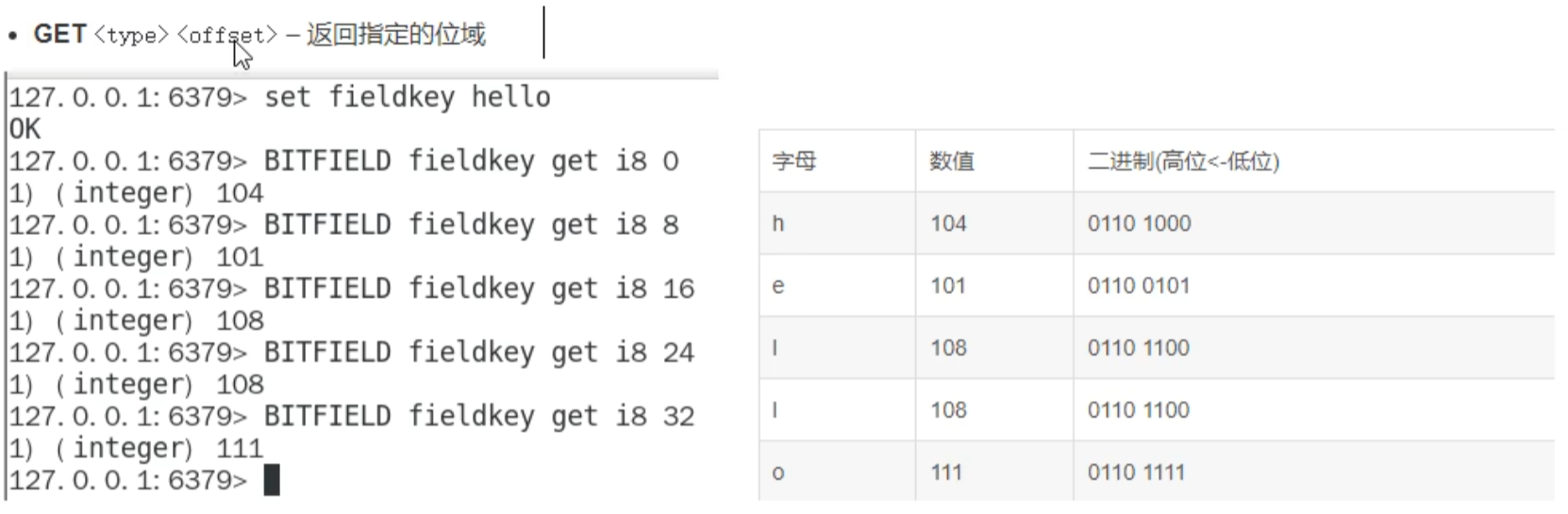

-128-127 超过则溢出



两个:: 就会有 empty


redis 持久化
Persistence refers to the writing of data to durable storage
- 通过 RDB 快照文件
(dump.rab)恢复,将磁盘的快照恢复到内存 - 通过 AOF 记录的命令进行恢复
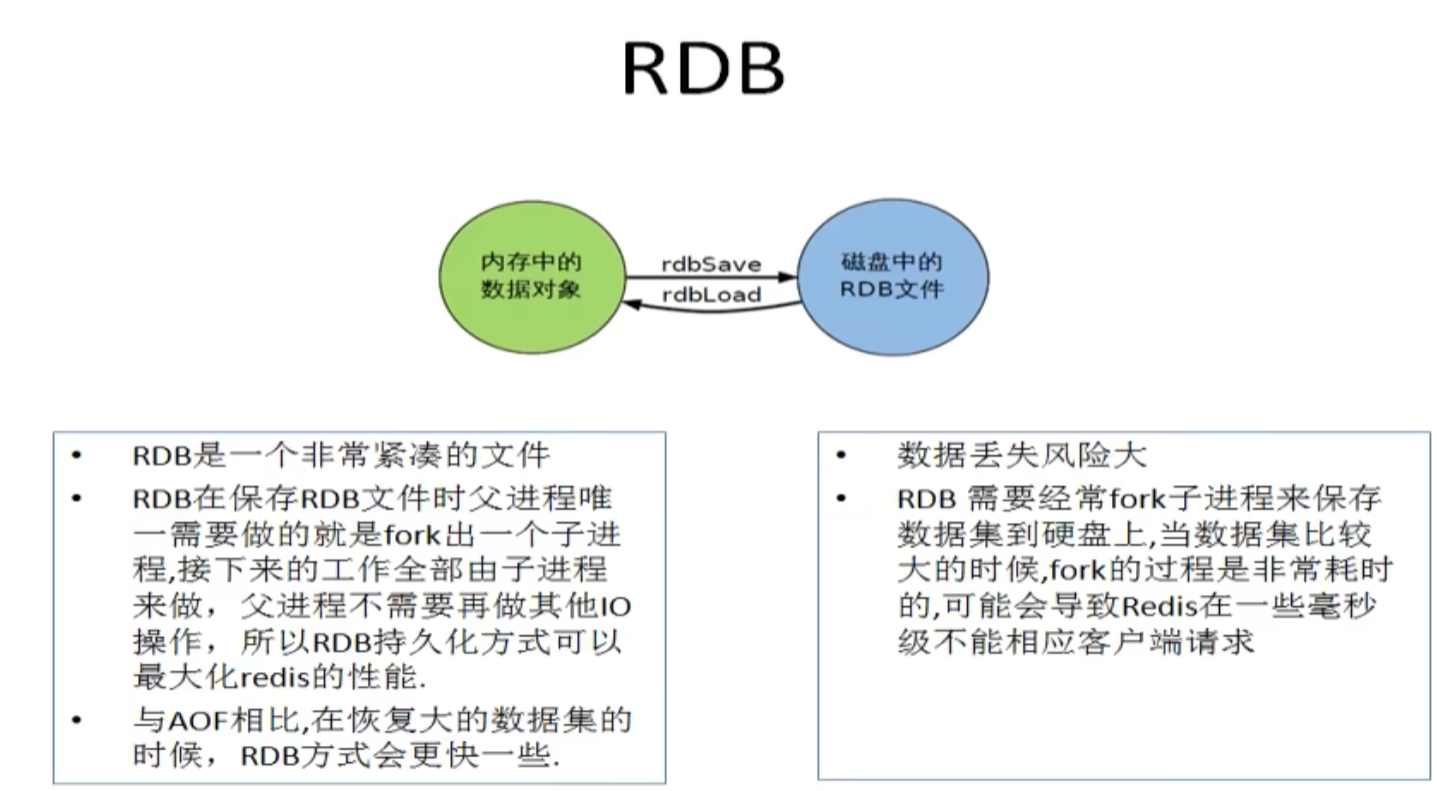
RDB
启用: save time num time 内触发 num 次就生效
禁用 : save "" 或 redis-cli config set save ""(非永久性) 依旧可以手动 save/bgsave 生成 RDB
-
路径修改
-
文件名修改: 配置文件搜
dump. -
配置文件搜索
config get dir获取目录 -
遇到的问题: 需要
dumpfiles文件夹权限更改
SAVE 阻塞,其他命令都会不能处理,线上禁止使用
BGSAVE: fork 一个子进行进行复制持久化,主进行可以同时修改数据
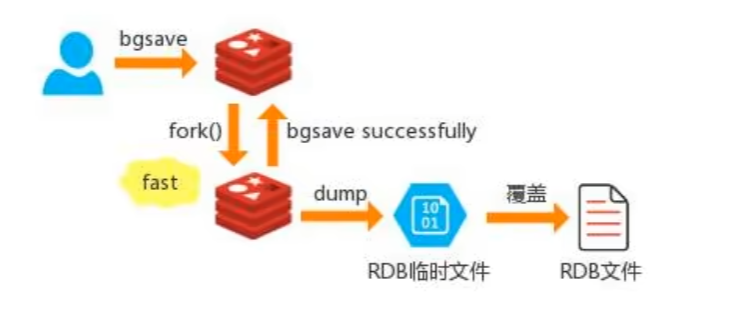
title:`fork()`
`fork()` 函数会创建一个完全和父进程相同的子进程,包括代码、数据和打开的文件描述符等。


title:`lastsave` `date -d`
`lastsave`于获取最近一次成功执行持久化操作(快照或AOF)的时间戳。它可以告诉你上次完成持久化的时间,对于监控和管理 Redis 实例非常有用


`date -d @16695455399`

title:RDB 优缺点
1. 适合大规模数据恢复
2. 比AOF快
3. 定时备份


- RDB 缺点
1. 在没有触发达到保存条件时发生意外的数据会丢失
2. fork()可能消耗性能大


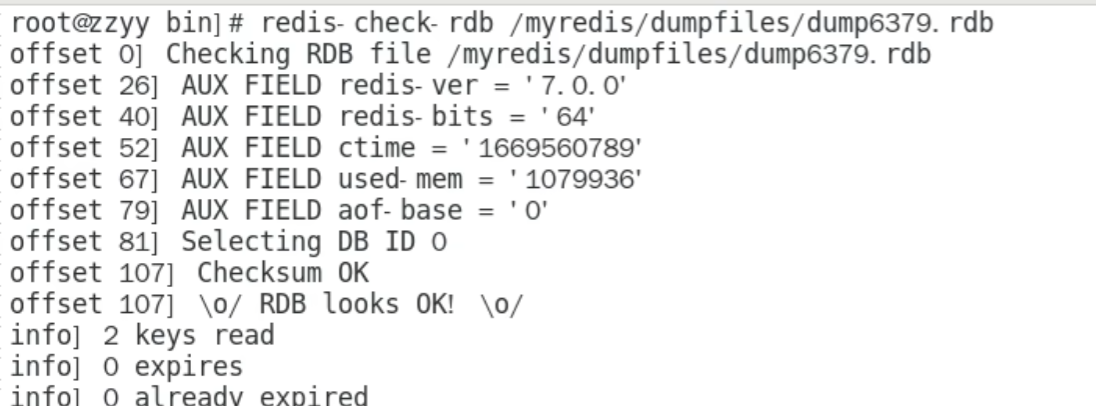
title:修复
check -rdb /myredis/dumpfiles/dump6379.rdb

写到一半断电导致破损了
优化配置

-
stop-writes-on-bgsave-error

-
yes: 如果在bgsave过程中, 发生写入错误,Redis将停止接收任何请求, 直到bgsave完成为止 -
no:即使在bgsave过程中,发生写入错误,Redis也会继续接收请求并尝试写入

rdbcopression压缩变小,消耗一点cpu

rdbchecksum 安全/一致性 建议 yes

rdb-del-sync-files 不用管

AOF
appendonly yes

三种写回策略
appendsync everysec

一般选 everysec, always 会导致 IO 太多,性能下降
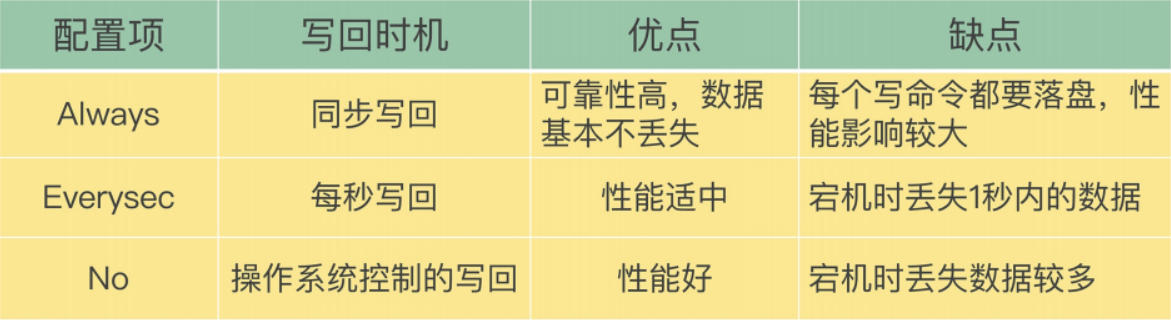
no 则取决与 linux 内核刷新数据的配置,通常 30 秒
保存规则

incr 文件内容

title:修复redis-check-aof --fix 文件名
> 如果只是数据被截断
`redis` 不会被影响,`redis` 会自动抛弃错误的数据,当如果错误的数据发生在文件中,后面的数据也会被抛弃,可能造成数据丢失
> 人为破坏 `incr` 文件会连接不上 `redis`

AOF 重写机制
appendfsync every/always/no
auto- aof- rewrite- percentage 100设置为100表示只要当前 AOF 文件的大小是上一次 AOF 文件大小的两倍或更多
auto- aof- rewrite- min- size 1k
incr 文件达到 1k的两倍就会重写


redis 事物
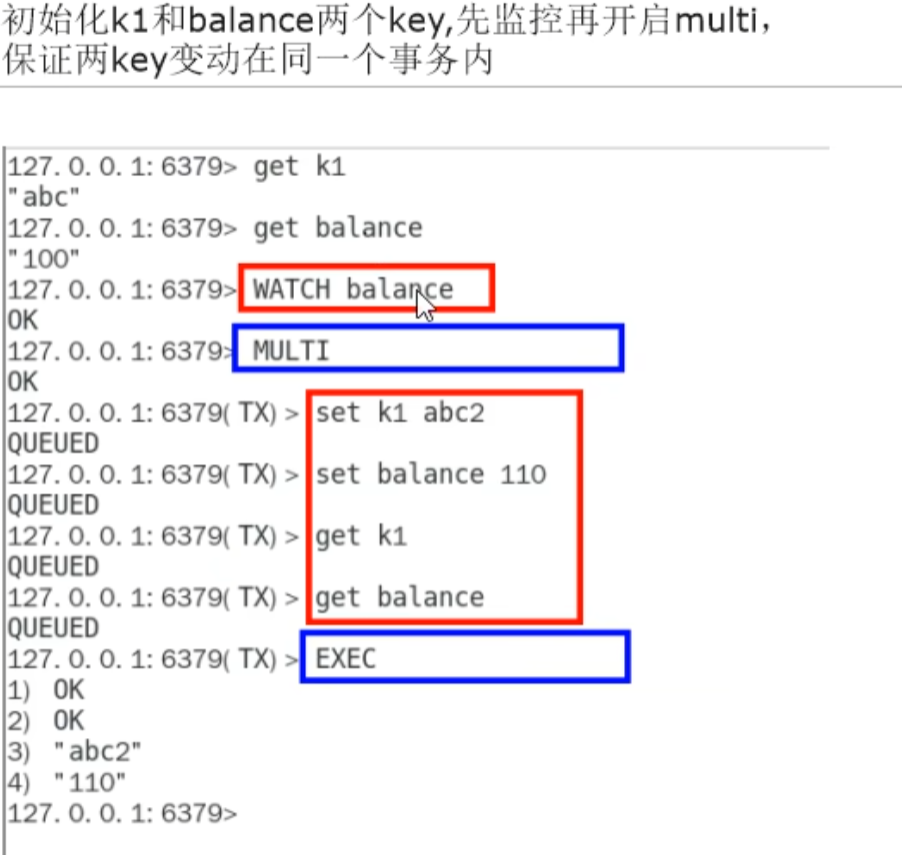
事物的要求 : 希望一个命令/多条命令能够合到一起成为一个不可分割,具备原子性,不被干扰打断,统一执行的批处理命令




正常执行
multi
exec
放弃事物
multi
discard
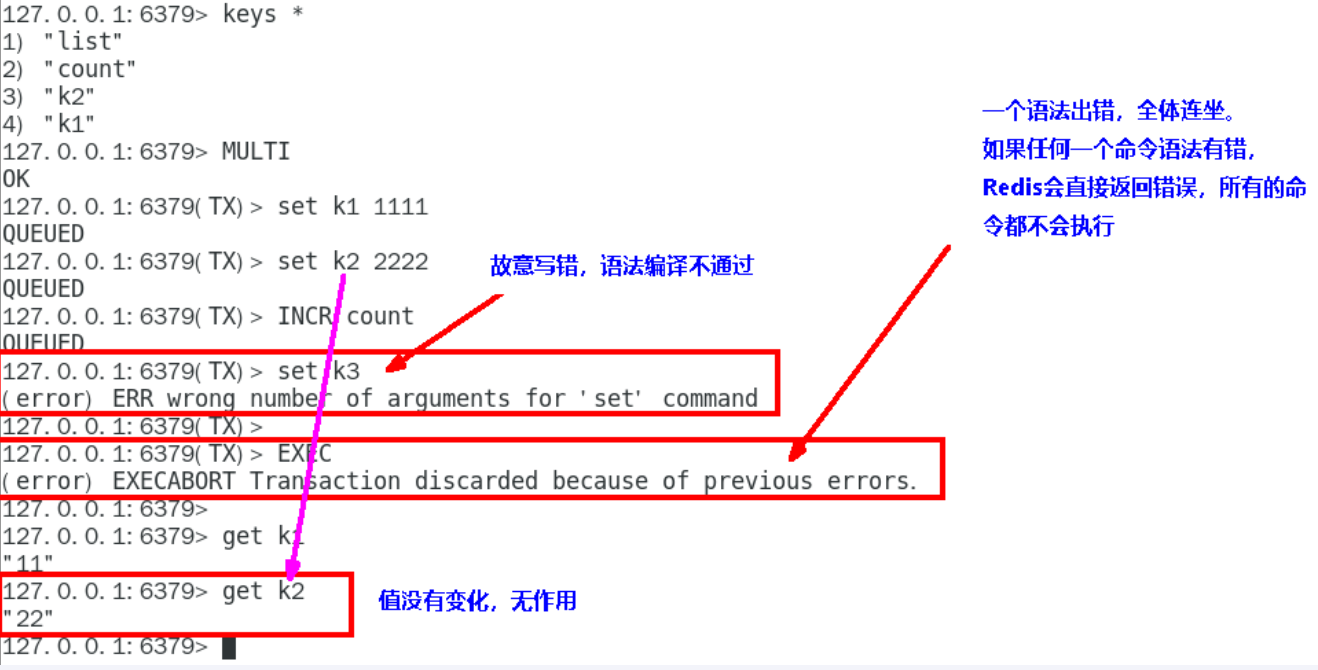
全体连坐
输入过程中检查出错误,redis 会直接返回错误,任何命令都不会执行
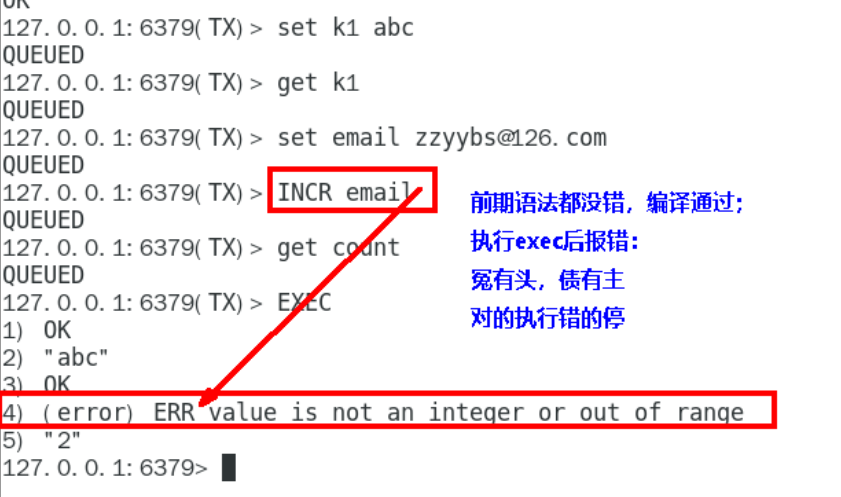
冤头债主
前期检查不出的错误,运行时才知道,只有出错的才不会执行

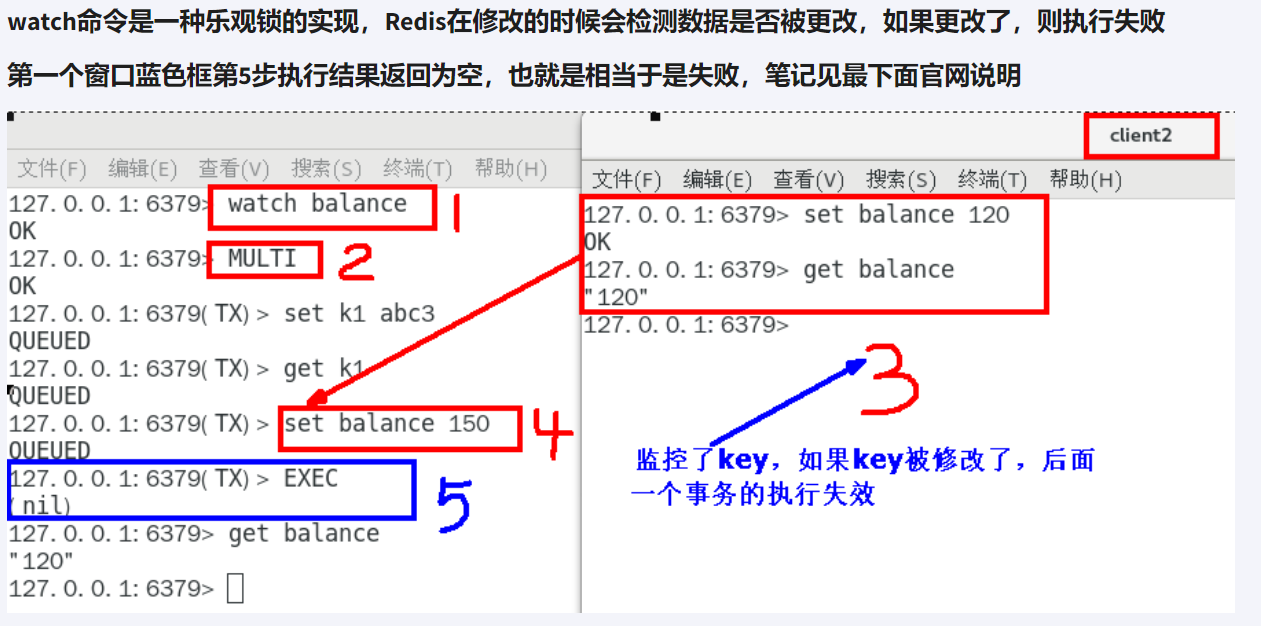
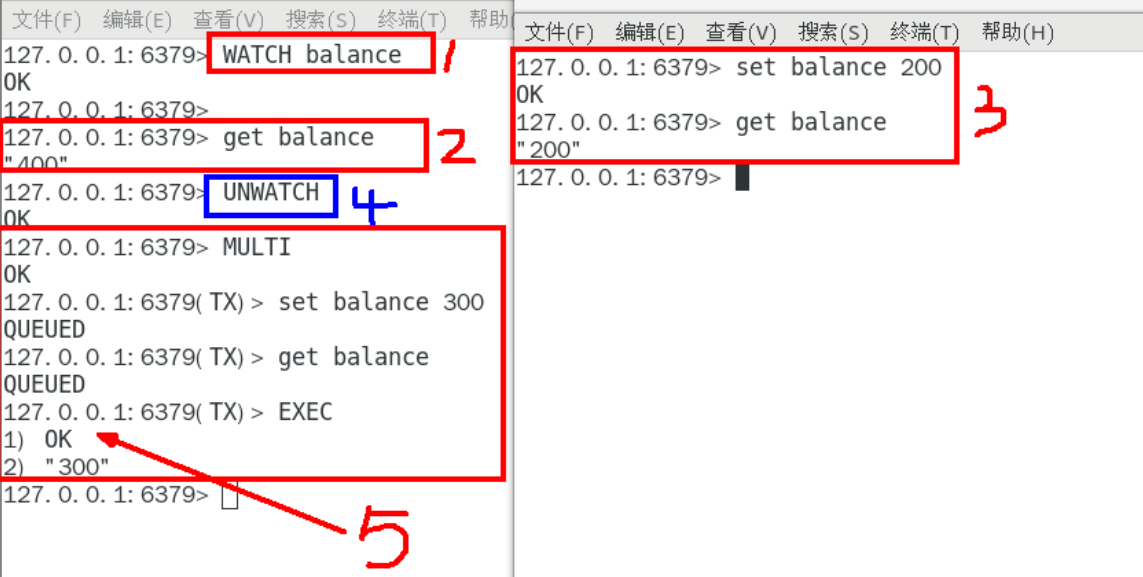
watch 监控
无加塞情况
有加塞情况
Redis 管道
Redis pipelining | Redis
如何优化频繁命令往返造成的性能瓶颈

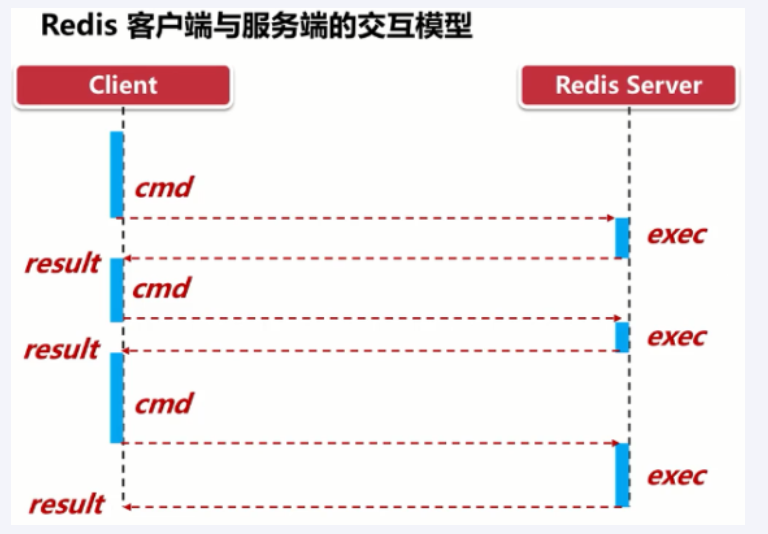

降低 RTT(Round Trip Time) 对性能的影响
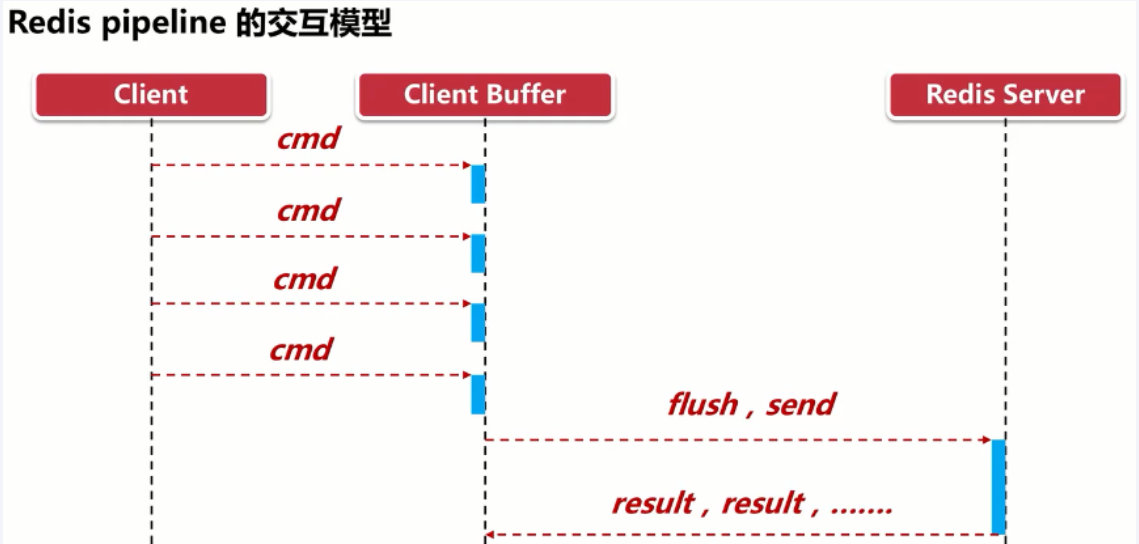
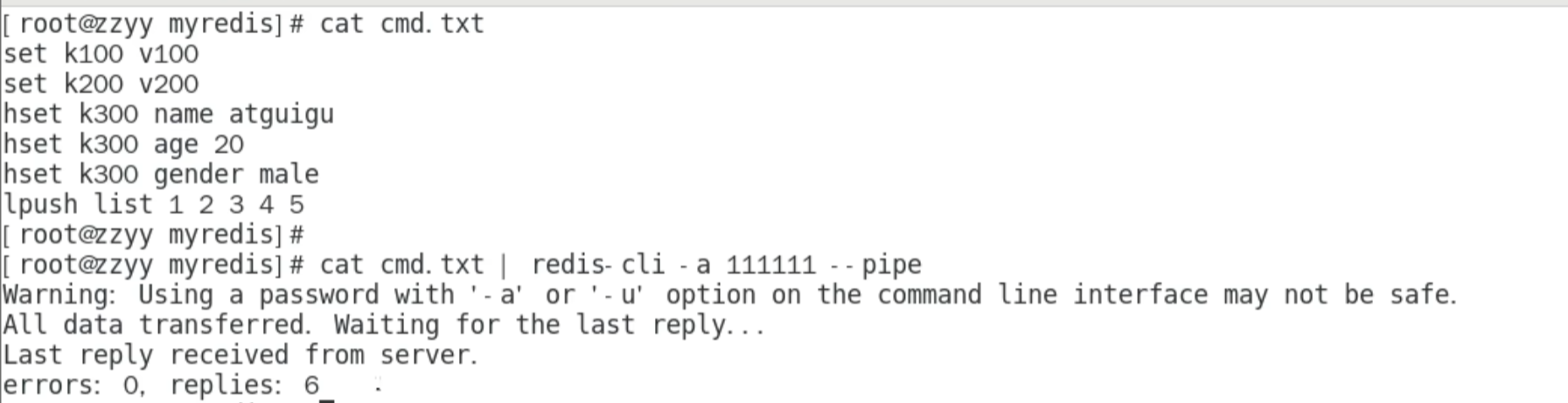

需要 linux 客户端和 服务端共同完成


Redis 发布订阅 (了解)



就是 redis 消息队列的前身雏形

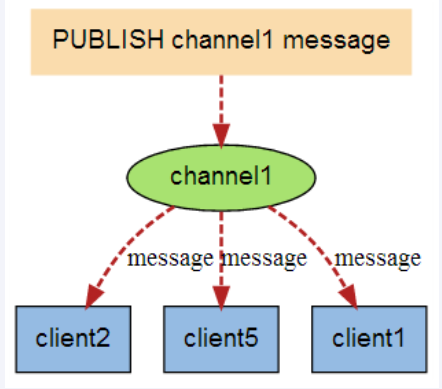
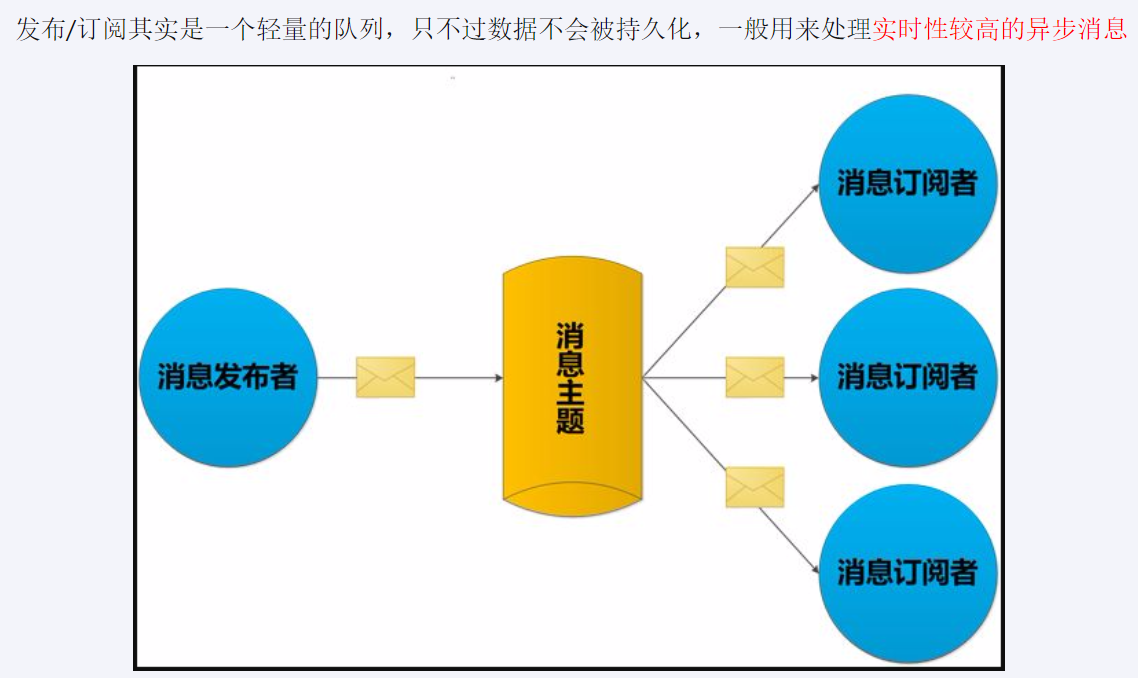
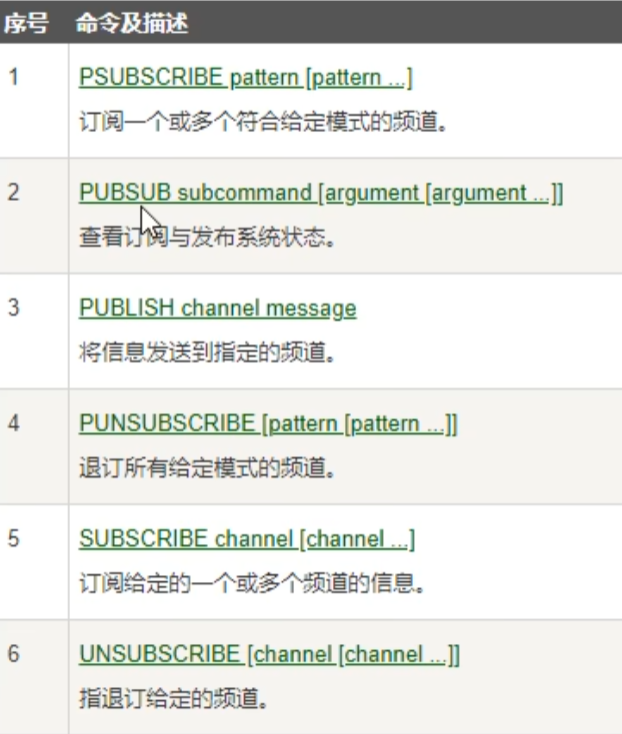
subscribe channel [channel ...]
-
publish channel message

-
publish pattern [pattern ...]

-
pubsub subcommand [argument [argument ...]]

-
unsubscribe [channel [channel ...]]
-
Punsubscribe [pattern [pattern ...]]

redis 复制(replica)
主从复制 : master 以写为主,slave 以读为主
当 master 数据变化时,自动将新的数据异步同步到其他 slave 数据库

配从库不配主库
配置
---通用部分---
bind 0.0.0.0 # 允许地址
protected-mode: yes #防止Redis实例在未进行任何安全配置(如requirepass/bind)的情况下被外界访问。
daemonize yes # 允许后台启动
logfile "/usr/local/redis/redis.log" # 日志路径
dir /opt/software/redis-7.0.3/data # RDB文件存放目录
appenddirname "appendonlydir" # AOF文件会在dir的位置上的appenddirname文件夹保存
appendfilename "appendonly.aof" # AOF文件名
appendonly yes # AOF 开启
`redis` 主从: 读写分离,容灾恢复,数据备份,水平扩容支撑高并发
主从:slave依旧可以作为其他slave的master(减少master的压力)
只有最顶层master可以执行命令,slave会复制之前的也可以复制
主机挂了从机会等待主机上线
中途变更:从机可以随时修改主机,修改后会自动清楚之间的数据,拷贝新master的
缺点:
挂了需要人工干预
系统繁忙时,slave导致延迟高
--- Master.conf-----
requirepass xxx #master设置
--- 主从Slave.conf(只需要改从库配置,无需更改主库配置)------
# 指定主节点的 IP 和端口(推荐)
replicaof 主库IP 主库端口
# 或者使用旧的方式
slaveof 主库IP 主库端口
slaveof no one #停止当前数据库和其他数据库的同步
masterauth xxx #slave设置
---- 命令行 ----
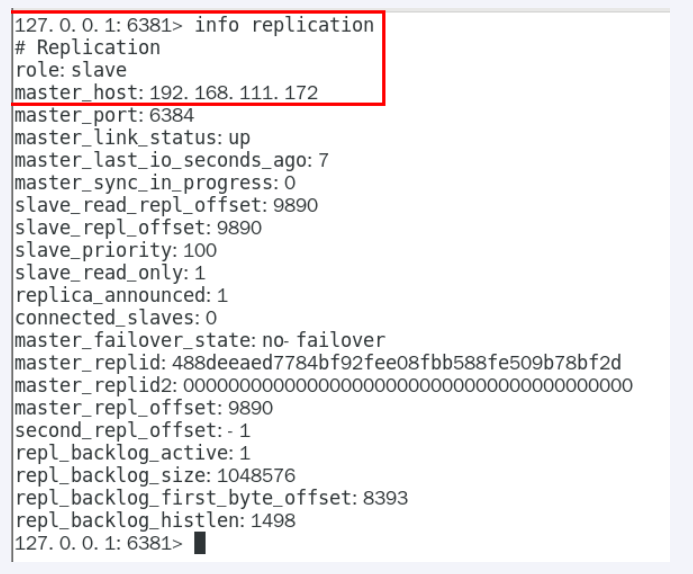
info replication #查看信息
slaveof 主库IP 主库端口 # 手动执行,当前会话有效
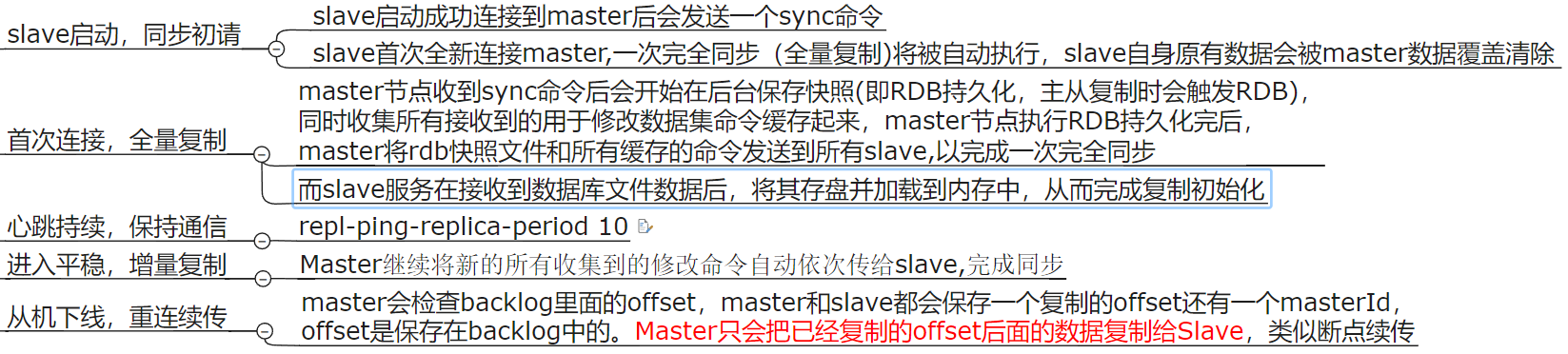
复制原理和工作流程
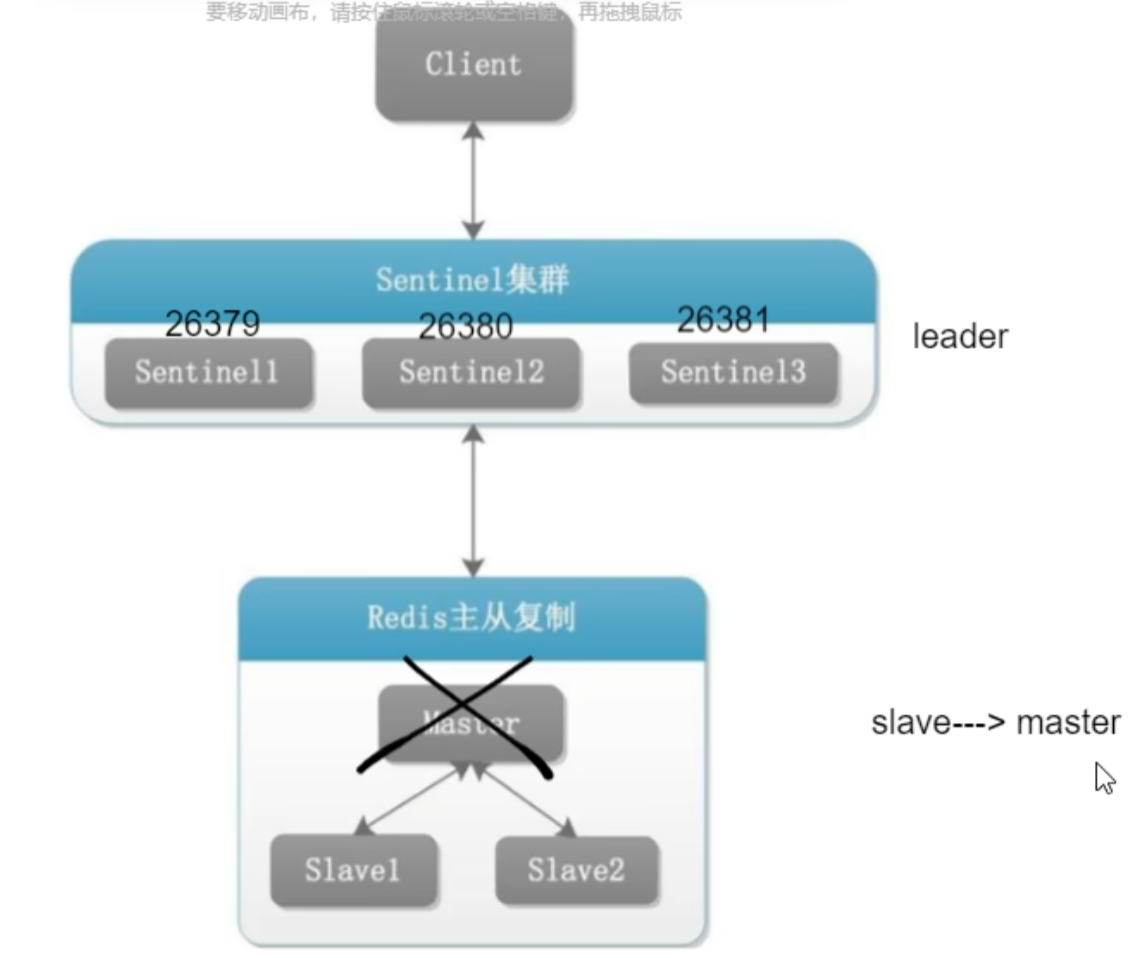
redis 哨兵sentinel

无人值守运维 : 将 slave 通过某种机制进行选取,进行主从替换
作用
主从监控: 监控主从 redis 运行
消息通知: 故障转移结果发送客户端
故障转移: 自动主从切换
配置中心: 通过连接哨兵来获得当前 Redis 服务器主节点地址
sentinel.conf 配置文件
在上一章复制配置好的情况下进行配置
sentinel.conf(配置好一个后直接拷贝改动)
配置文件







解释

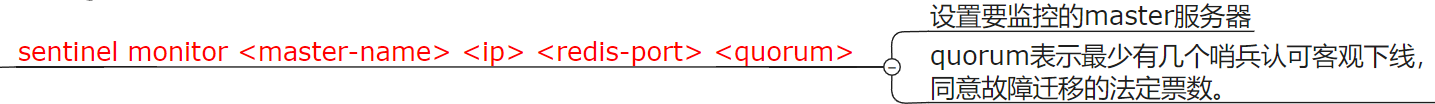
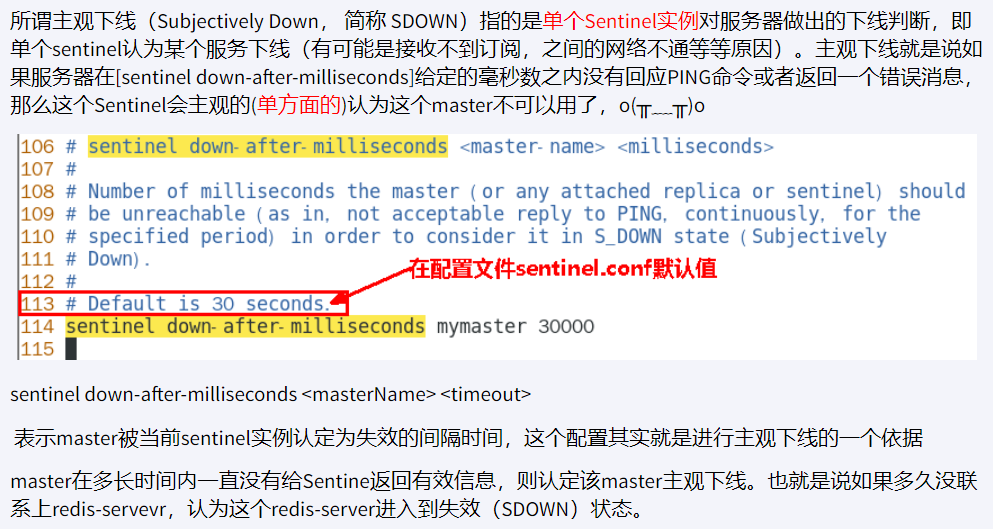
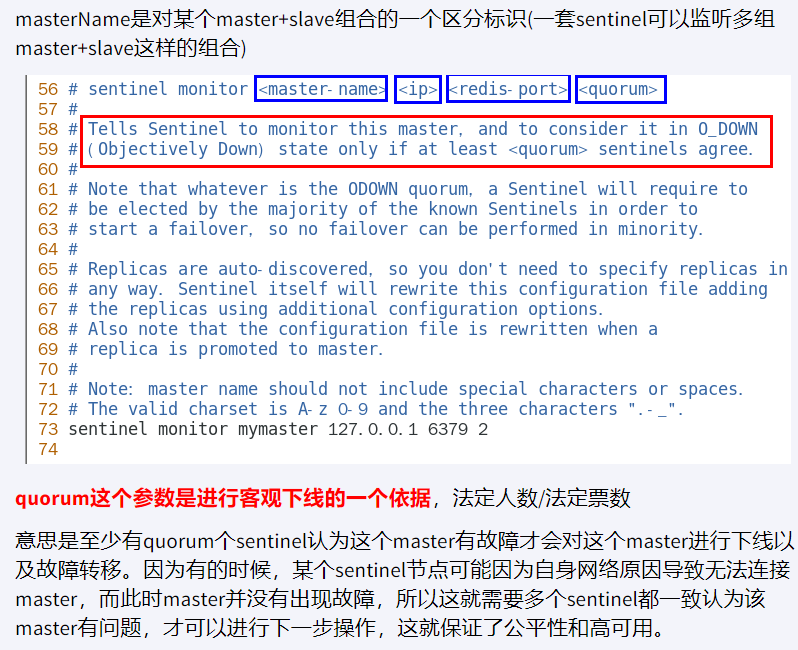
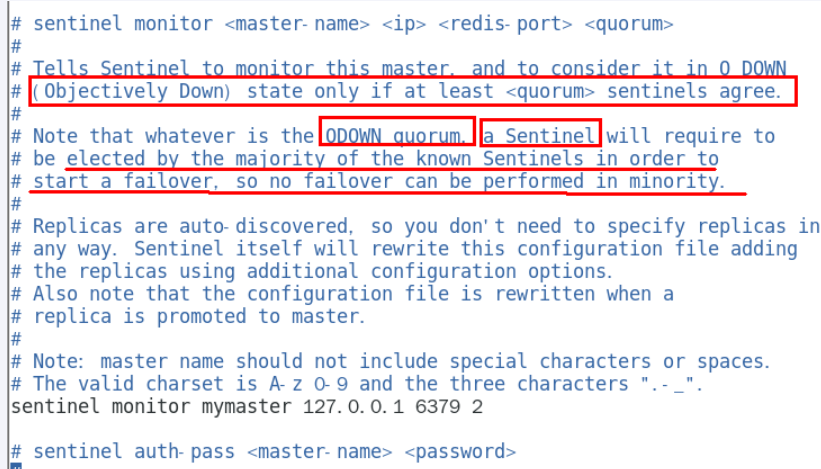
sentinel monitor <master-name> <ip> <redis-port> <quorum>

quorum : 2 即 2 个哨兵同意就行


网络拥堵,黑客攻击,网络波动等等,哨兵之前互相沟通,来判断是否真的故障了,有时只是某个哨兵自身问题
sentinel auth-pass <master-name> <password>

启动集群

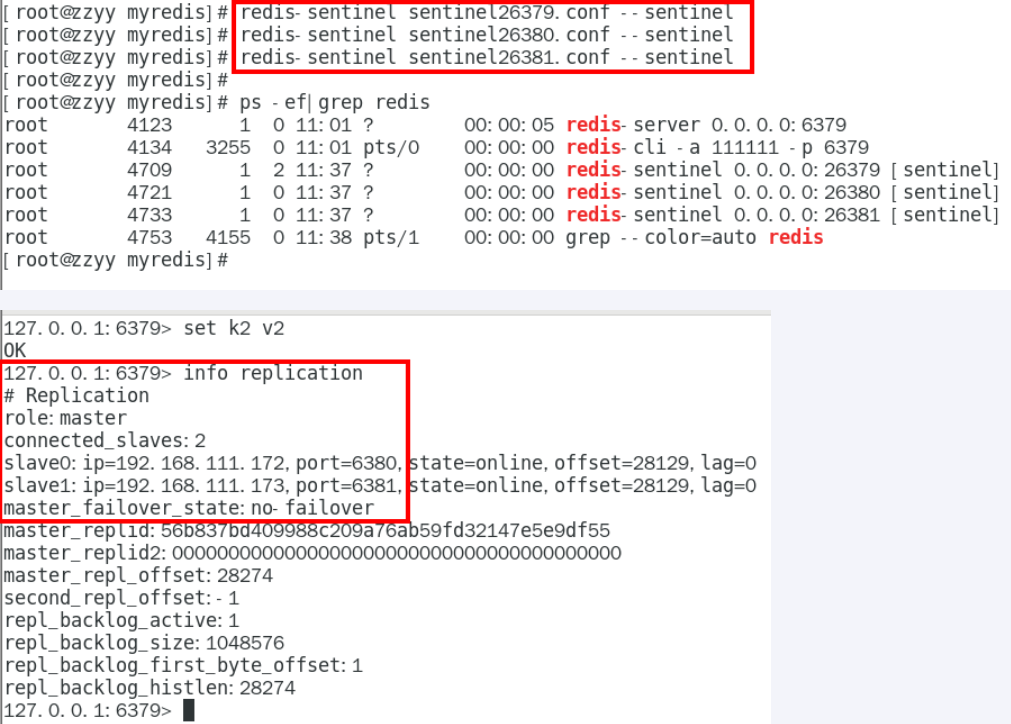
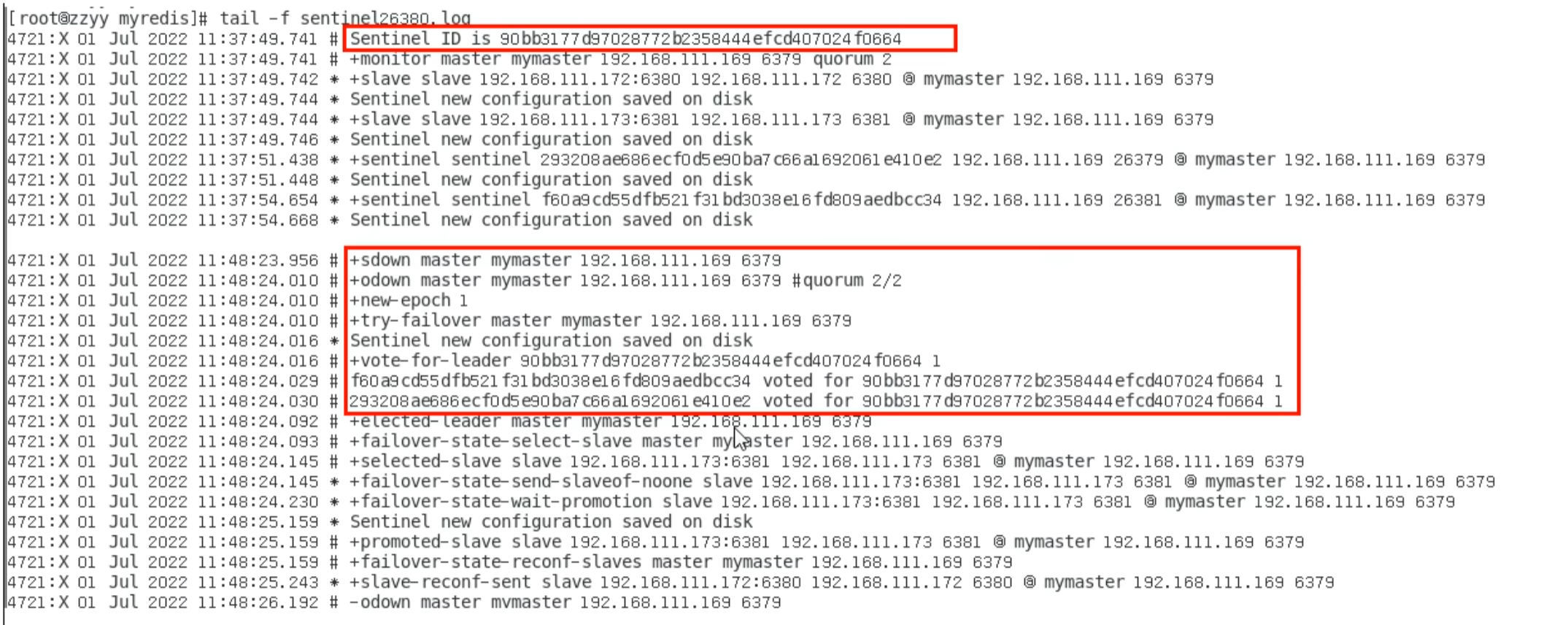
sentinel log
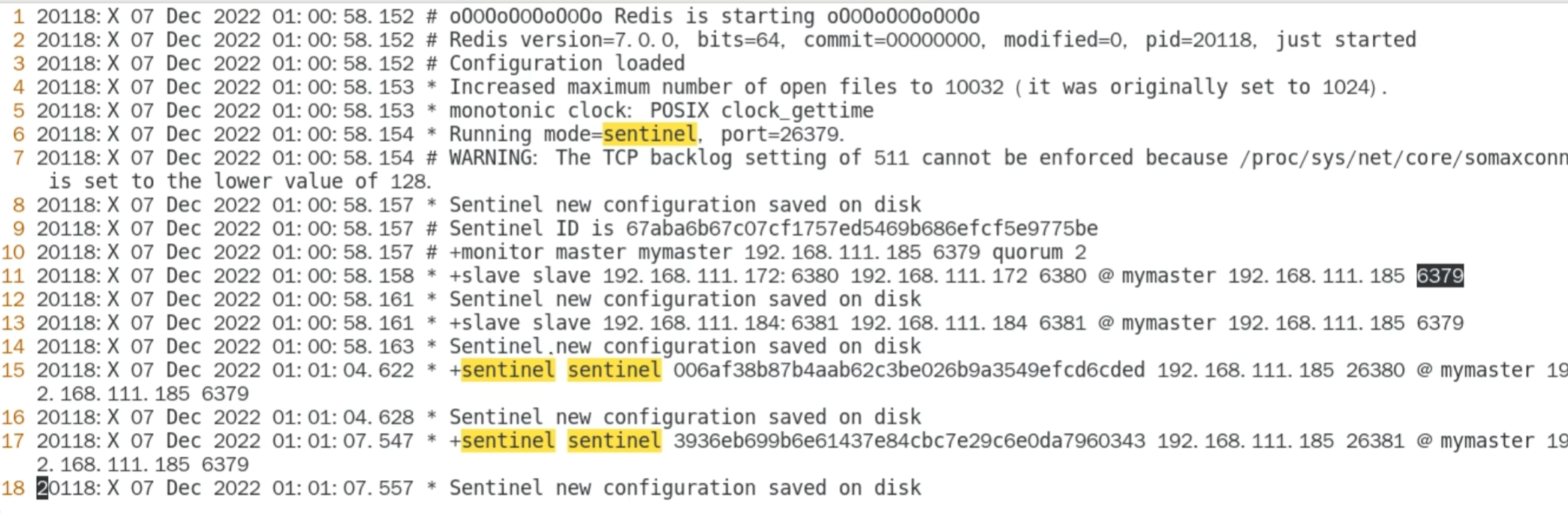
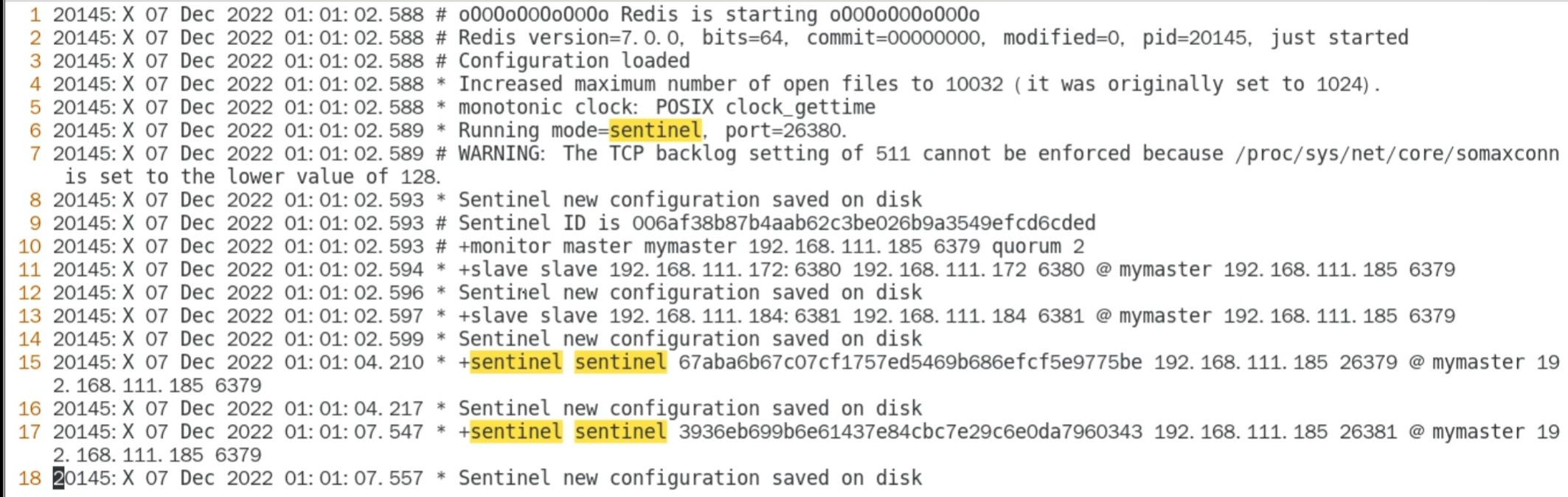
conf 文件被自动修改
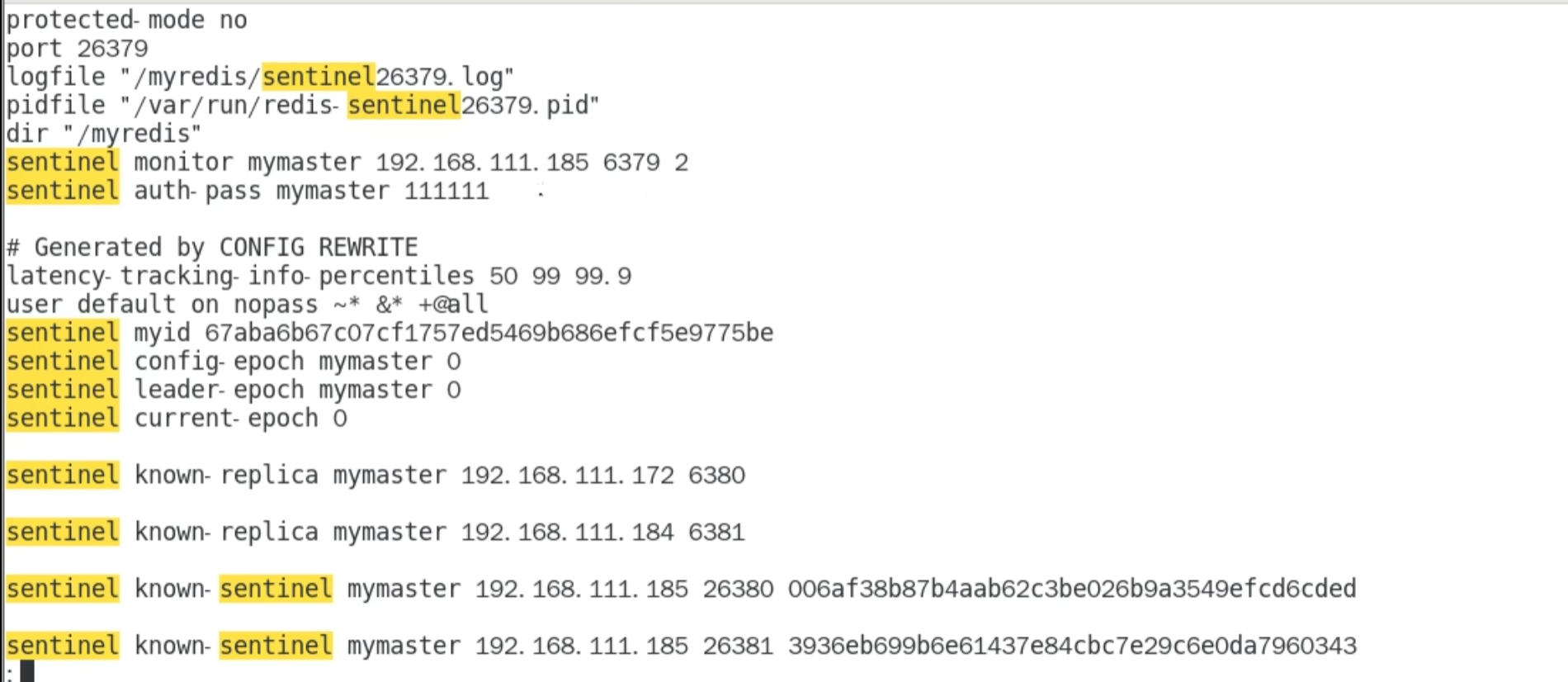
关闭 master 接近 1s ,后台进行了选举,同时 slave. conf 的文件也会被修改
被选为主机的 conf 文件内容被自动删除

被选为 slave 的自动被修改



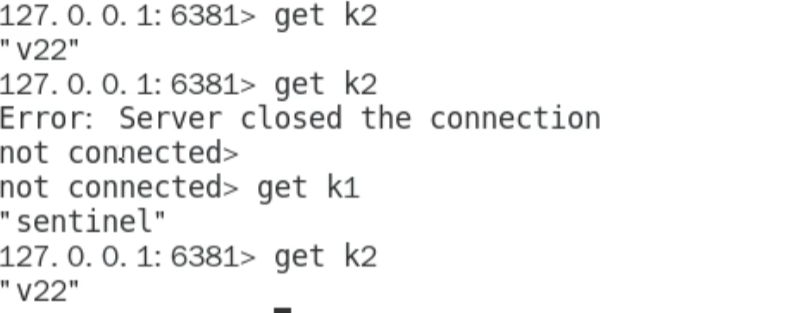
第一次失败是因为需要进行网络的重新读取和规划,告诉你原有的连接被断开了,可能需要重发一次心跳包,重新续接上去
剩下的两台slave其中一台会被选为master
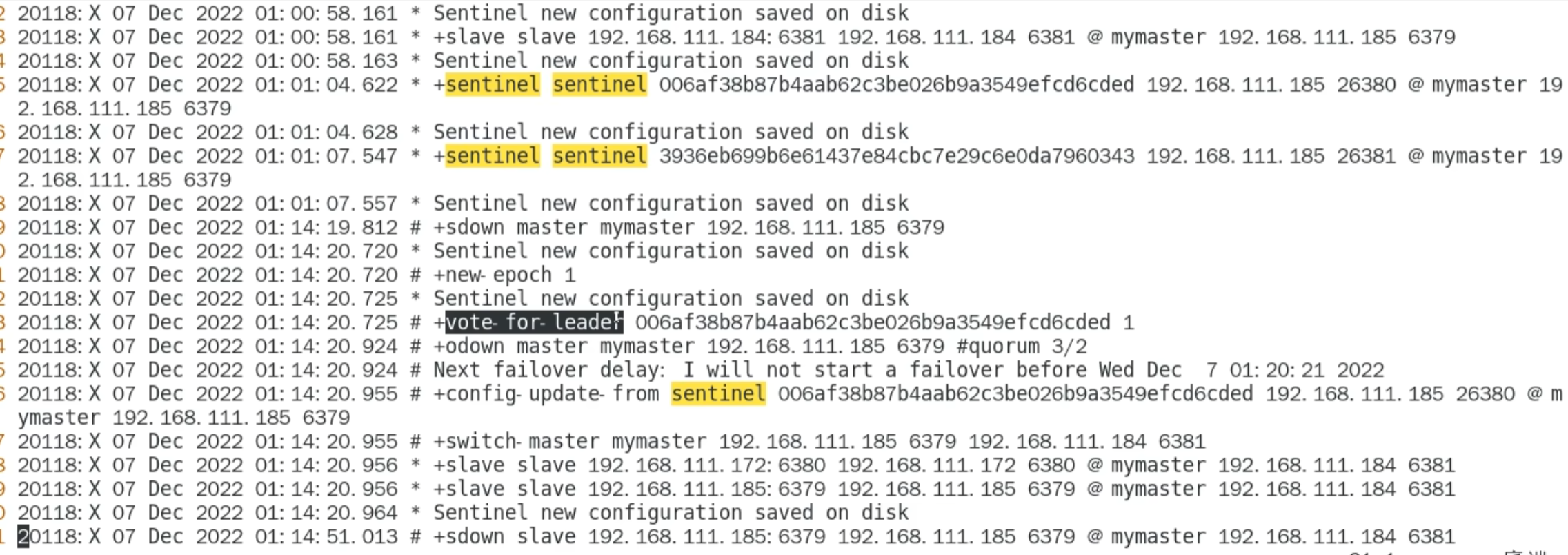
即使之前的 master 回来,也不会成为现在的 master 了

小问题

哨兵的运行流程和选举原理

SDown主观下线(Subjectively Down)

2.
ODown客观下线 ( Objectively Down)
3. 选出哨兵
三个中选出一个 leader, 这个 leader 选出 master
4. 选举日志


- 选举 Raft 算法

- 由哨兵开始推动
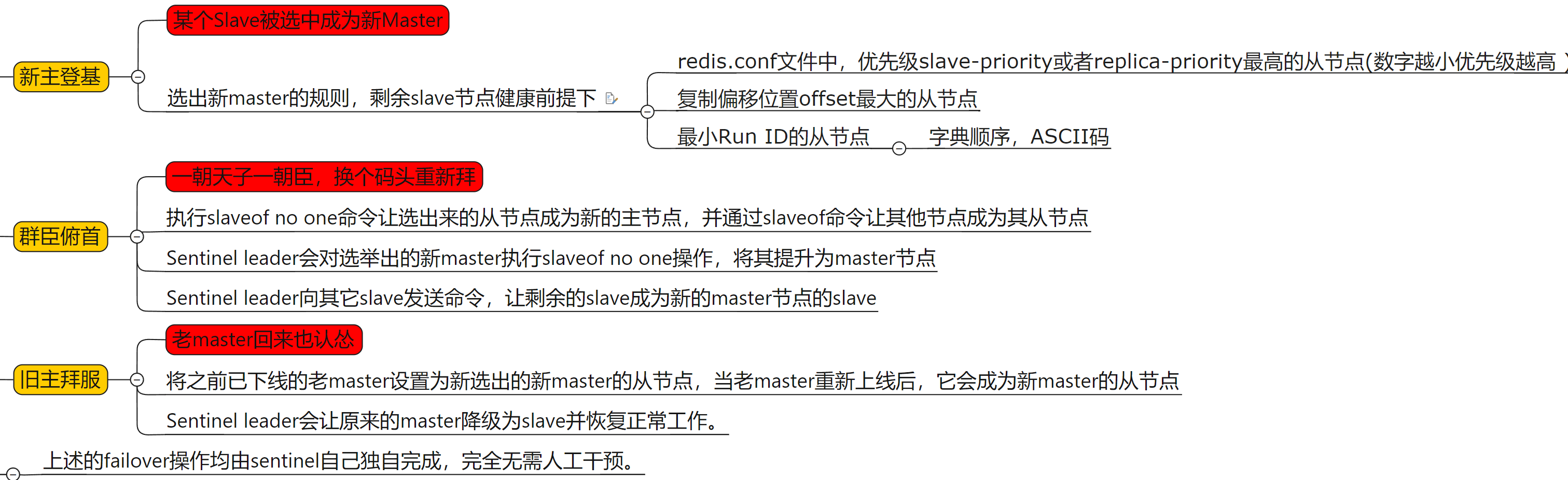
故障切换流程并选出一个新的 master
- 选出新
master
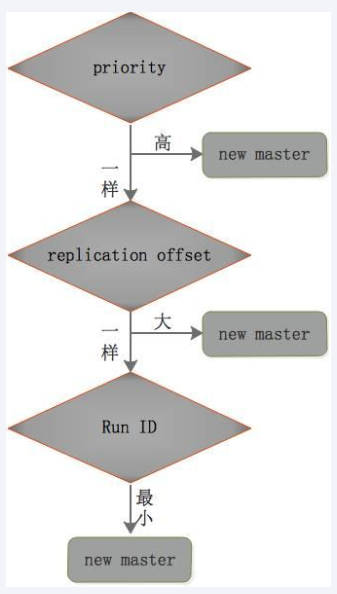
复制偏移量 (replication offset) : 由于网络等原因,两个slave不一定一样大- 生成
master, 别的变成master的slave
- 将已下线的老的
master设置为新选出的 master 的从节点





使用建议

虽然能够无人值守的故障迁移 : 但是选举哨兵 leader 和生成新的 master,少说需要 5-10s, 这期间的数据就会丢失
redis 集群 (cluster)
redis-cli -a password -p 6385 -c
-c 进行路由传递

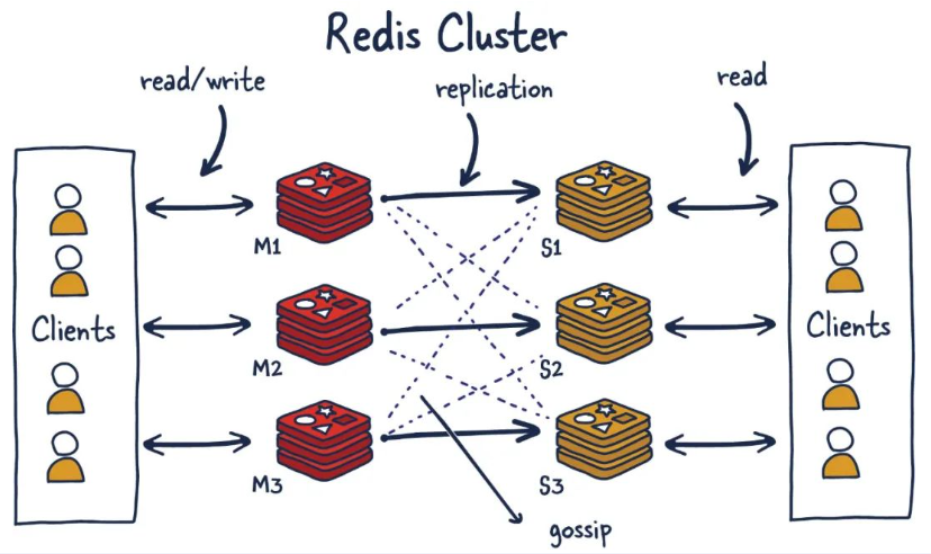

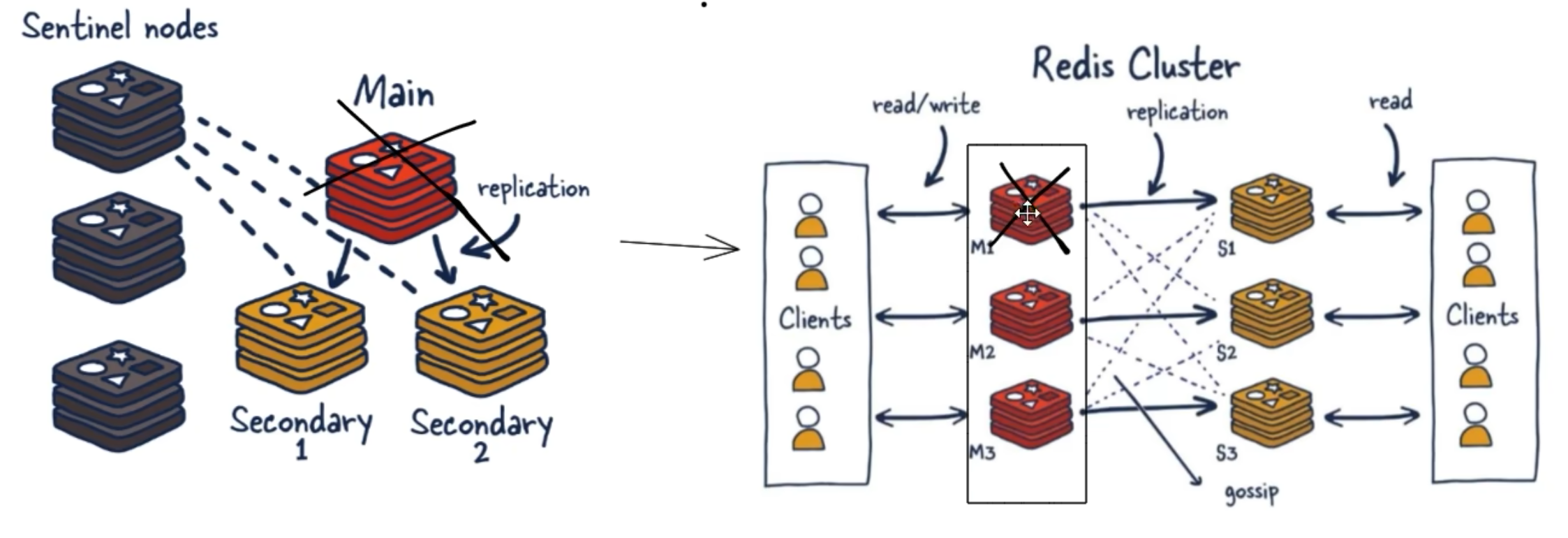
不再需要之前的哨兵
作用

集群算法-分片-槽位 slot


优势

读写都是同一个槽位

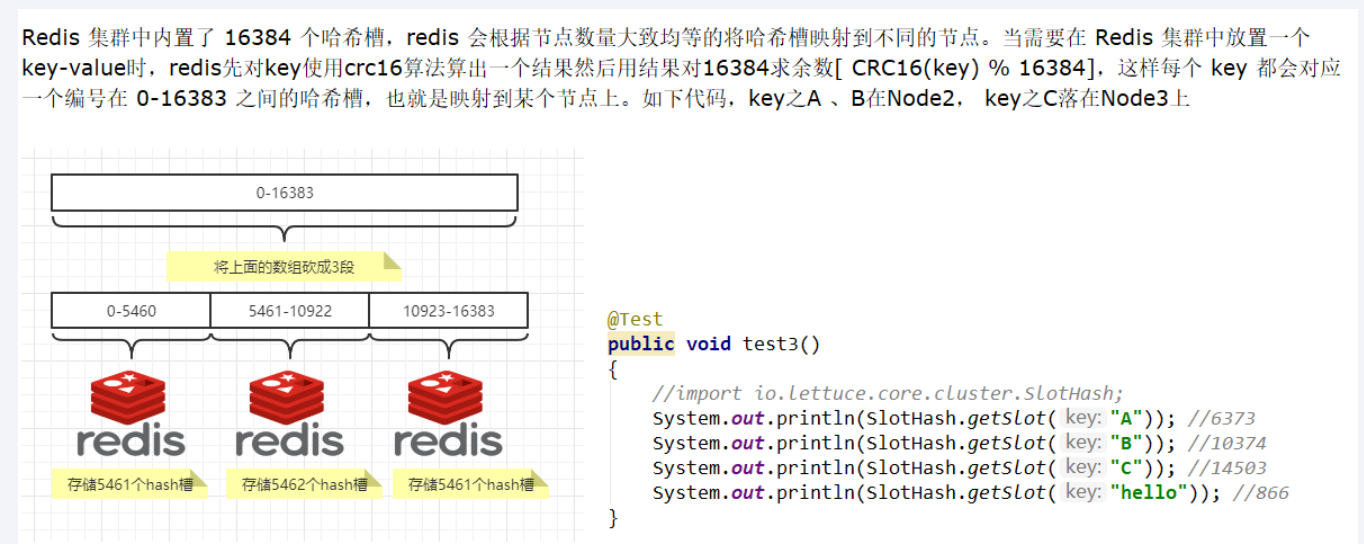
键值会用 CRC16 算法进行校验和,然后对 16384 取模,得到一个槽位的编号(如 1234 号)

哈希槽位映射
哈希取余分区
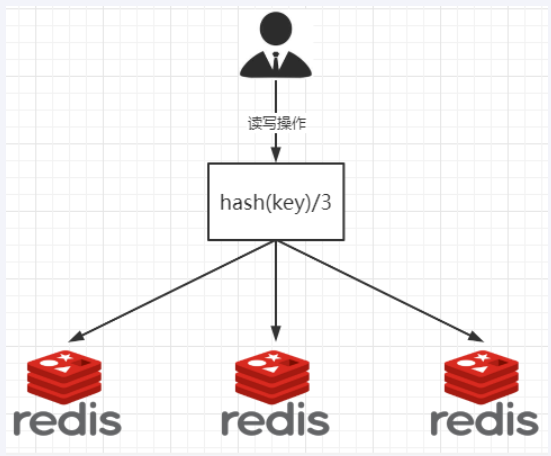

一致性哈希算法分区
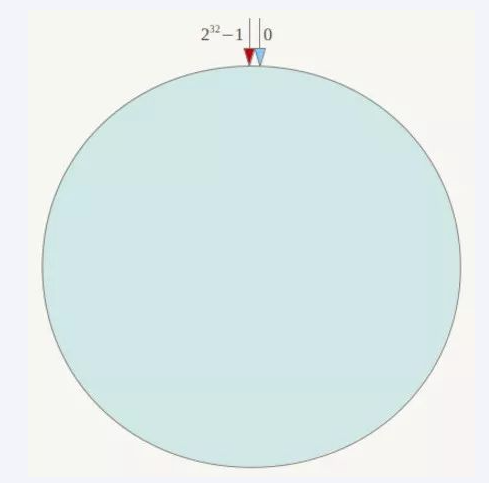
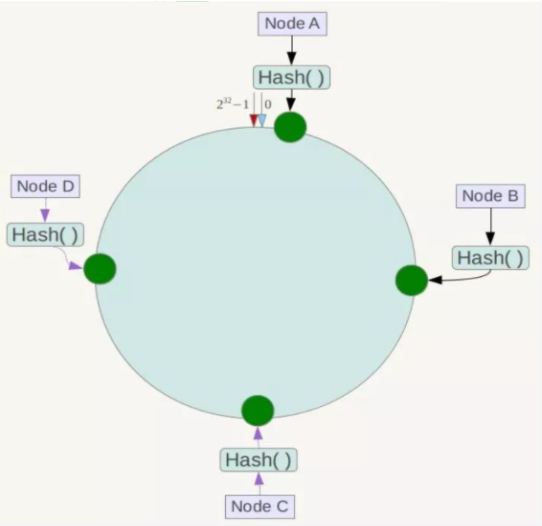
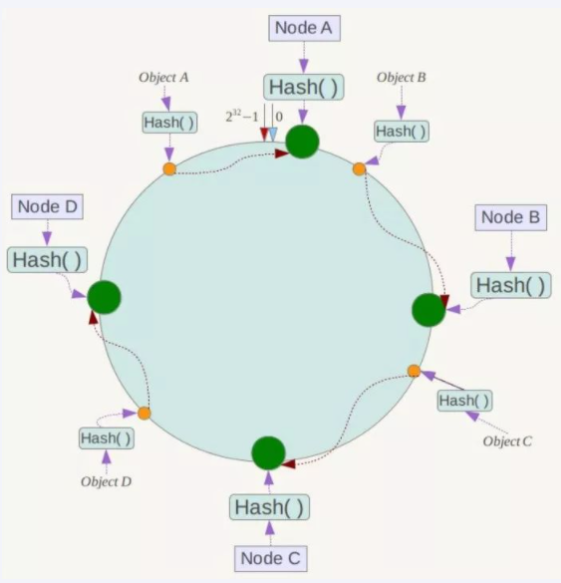
一致性哈希算法分区 : 所有的 hash 值构成一个全量集,逻辑控制使其首尾相连形成一个闭合空间,所有哈希值都落到环上,服务器节点也根据哈希落到环上,然后值会顺时针找到最近的服务器节点进行存储
优点 : 容错性,拓展性
缺点: 服务器太少时会出现数据倾斜问题

提出一致性 Hash 解决方案,目的是当服务器个数发动变化时,尽量减少影响客户端到服务器的映射关系
算法构建一致性哈希环



redis服务器 IP 节点映射

key落到服务器的落键规则

优点
-
容错性

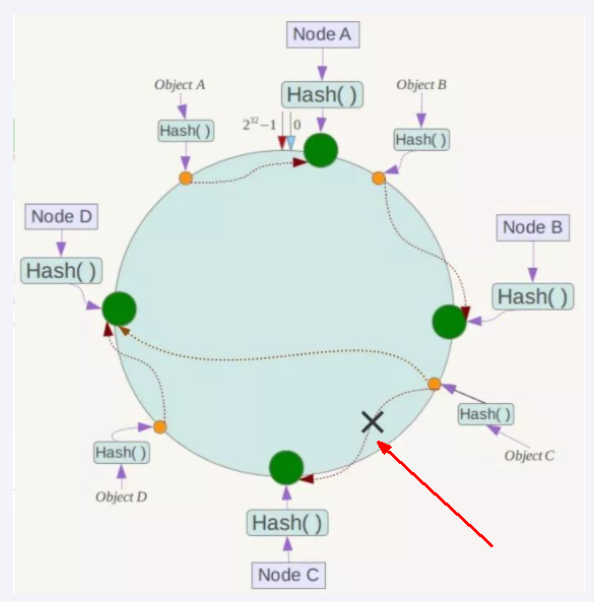
-
拓展性

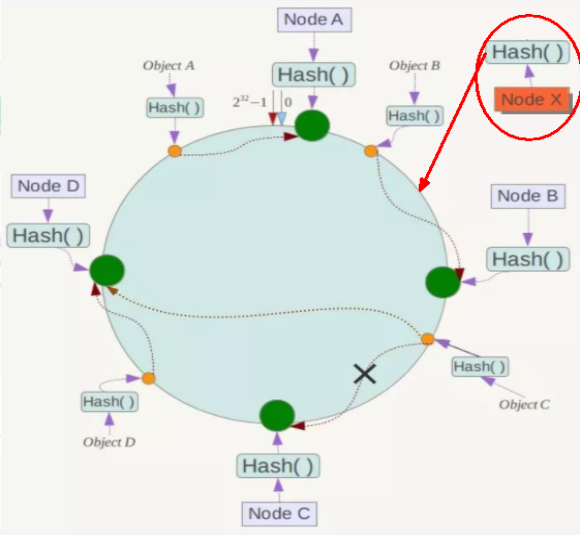
缺点


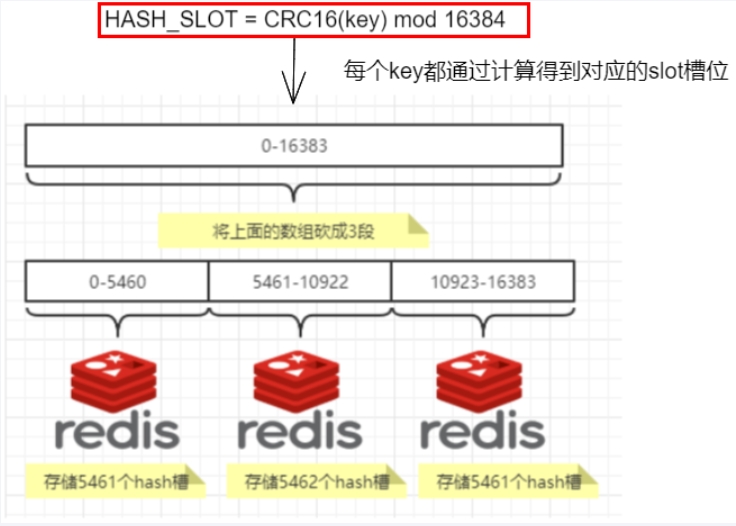
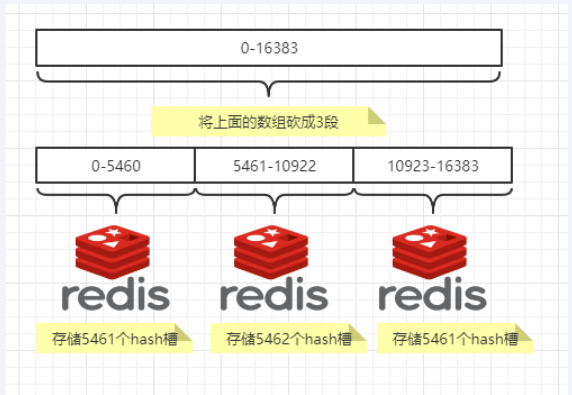
哈希槽分区


哈希槽分区
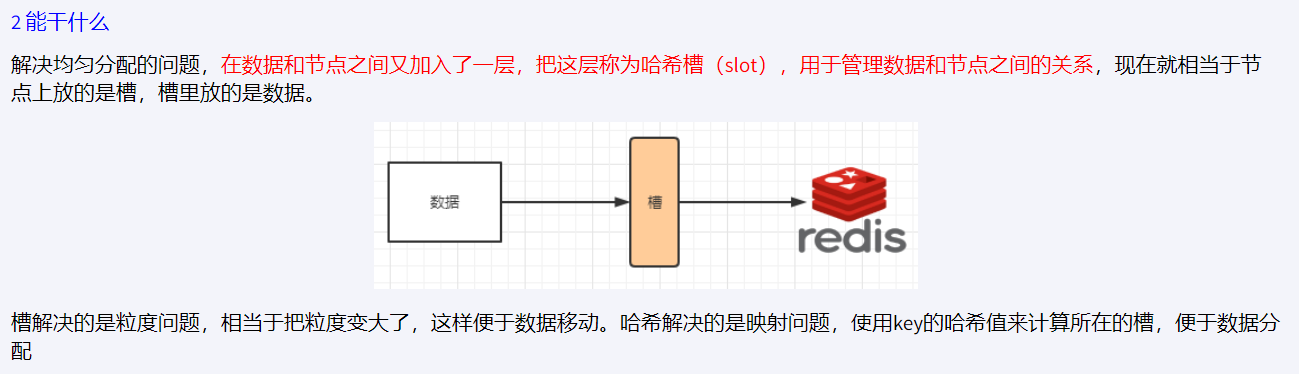
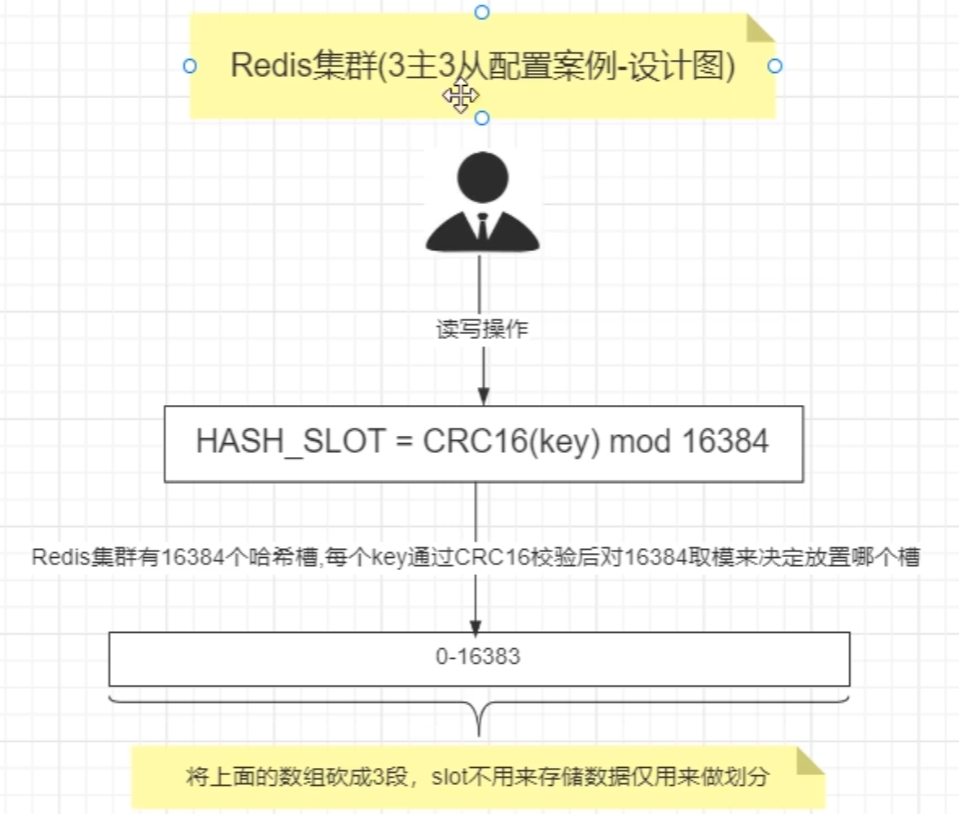
哈希槽分区 : 在 数据 和 节点 中加了一层 哈希槽 (16384),来管理 数据和节点间的关系, 槽 解决了粒度问题,哈希 解决了映射问题,
redis 会将大致相等的哈希槽分别映射到不同节点上
哈希值对 16384 取模,余数是几落到对应的槽里


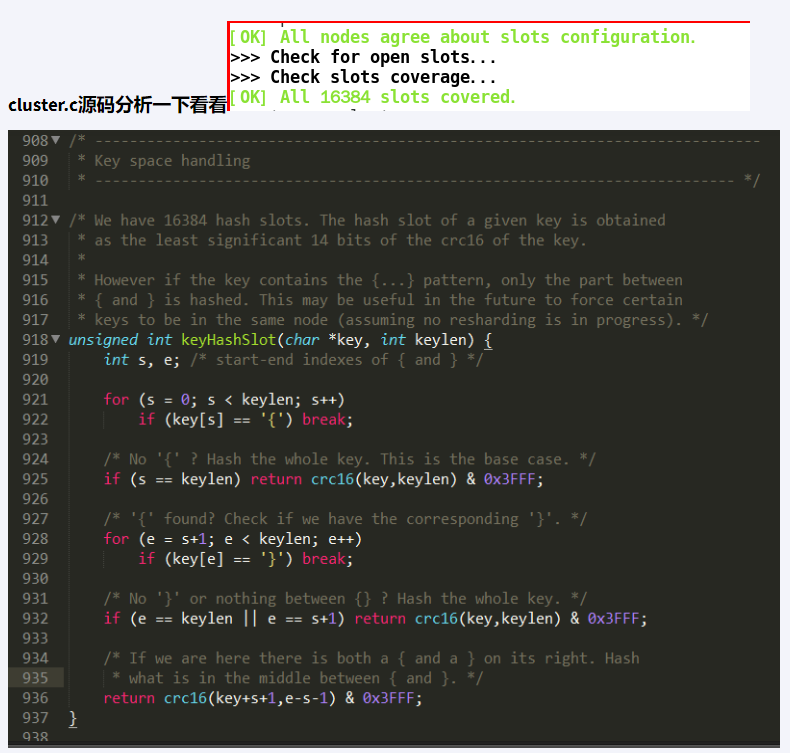
HASH_SLOT= CRC16(key) mod 16384
- 哈希值计算

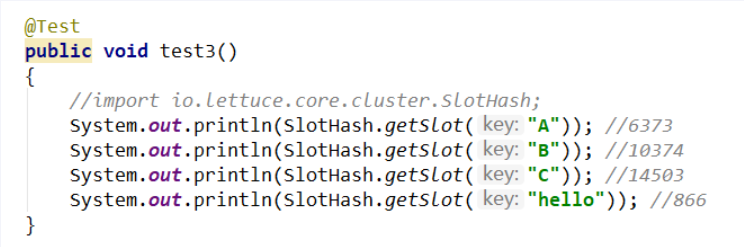
为何 redis 集群最大槽数是 16384 个

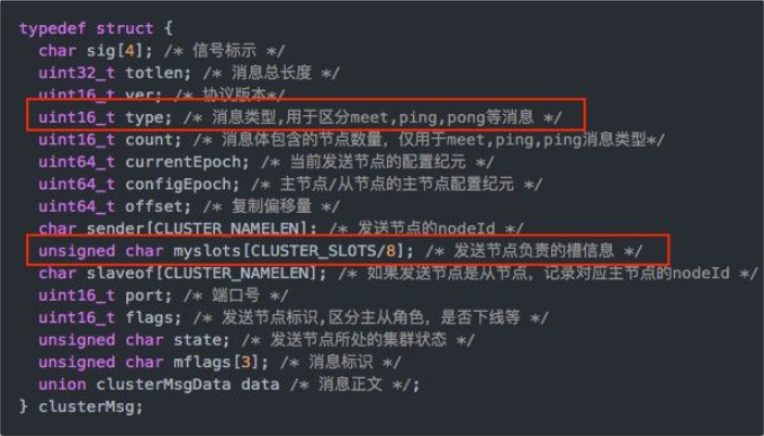



redis 集群不保证强一致性,在特定条件下,redis 集群可能会丢掉一些被被系统收到的写入请求命令

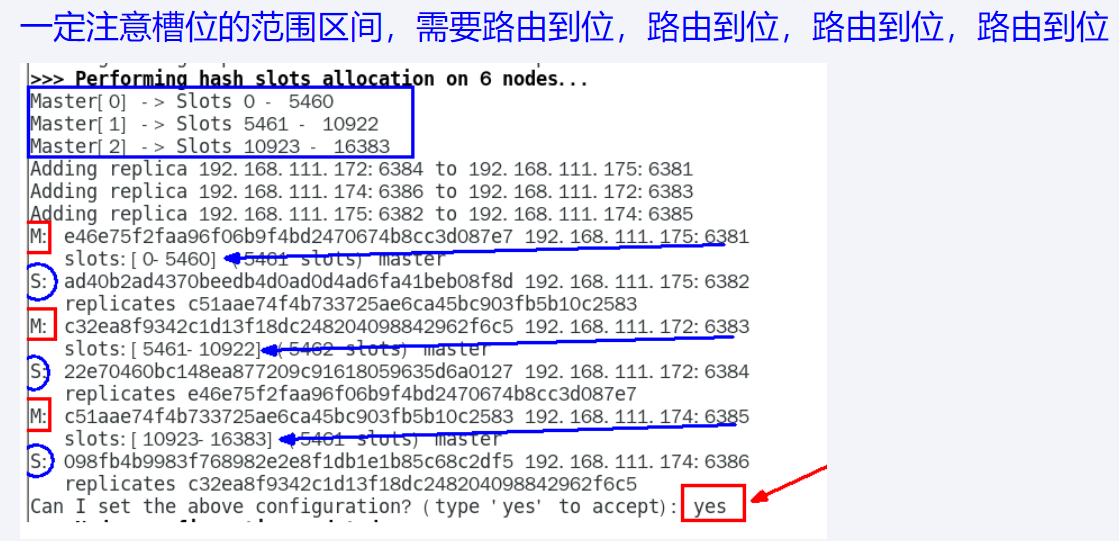
集群环境搭建步骤
三主三从 redis 集群配置
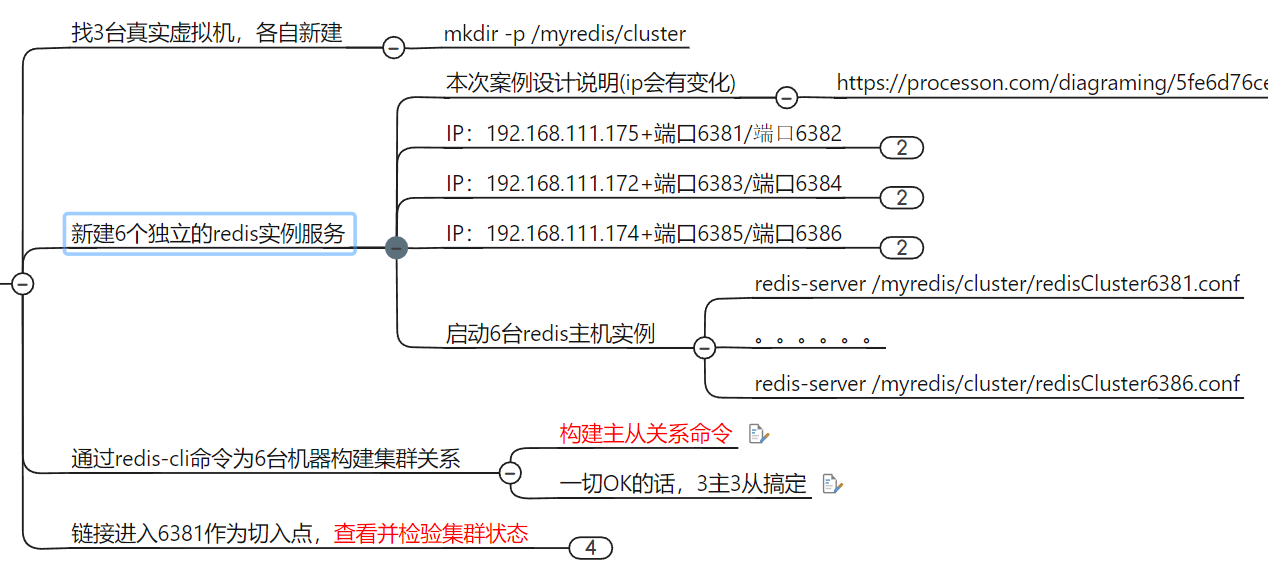
1. 新建6个配置目录 mkdis -p /myredis/cluster
2. 配置6个配置文件
3. 构建主从关系

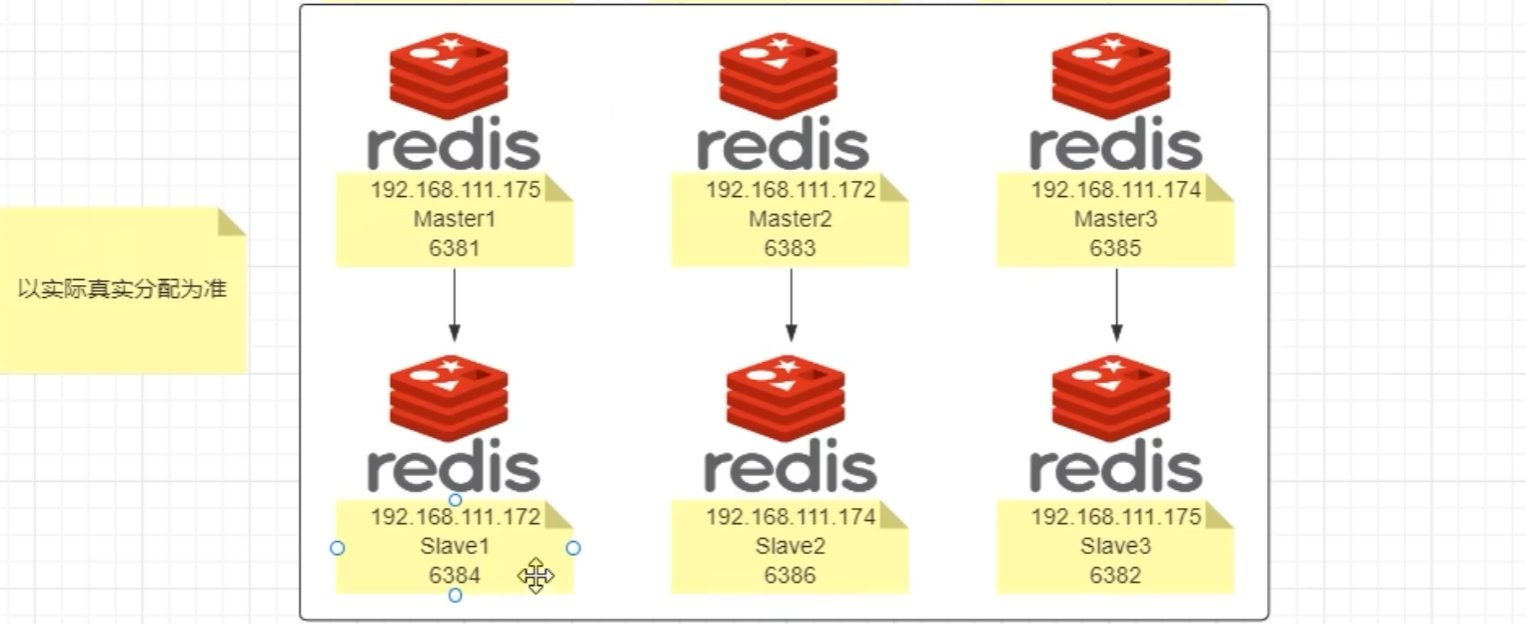
不一定按照写的分配, 以实际分配为准

主,从的配置文件完全一样,如下(视频 6 台配置文件全部都是下面内容)
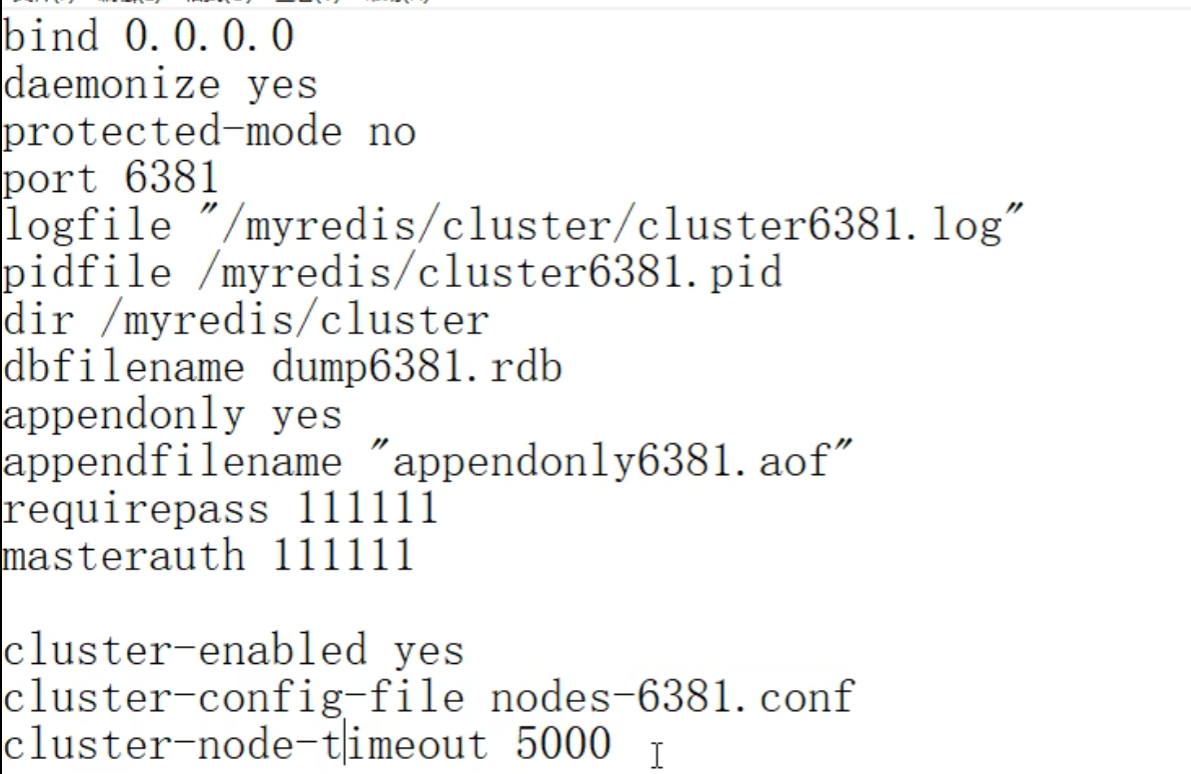
5000ms = 5s
3.构建主从关系
不一定按照写的分配, 以实际分配为准
redis-cli -a password --cluster create --cluster-replicas x
ip1:port1 ip2:port2 ip3:port3 ip4:port4 ip5:port5 ip6:port6



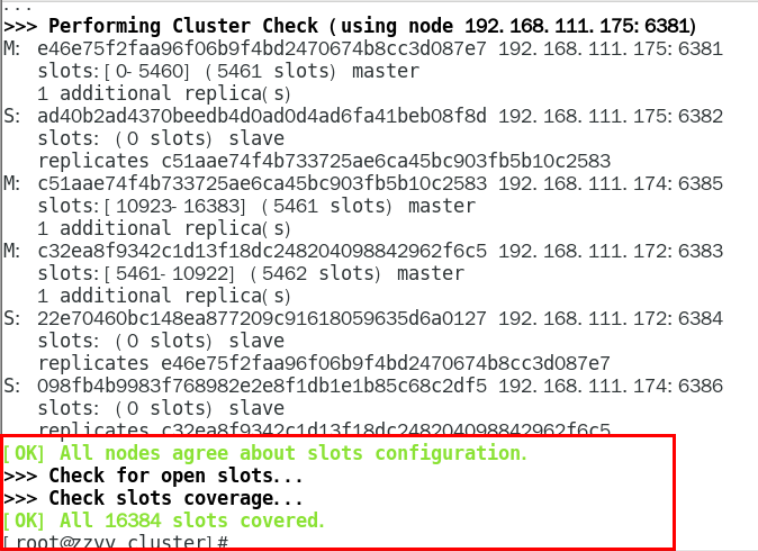
以 6381 为切入点,查看并检验集群关系
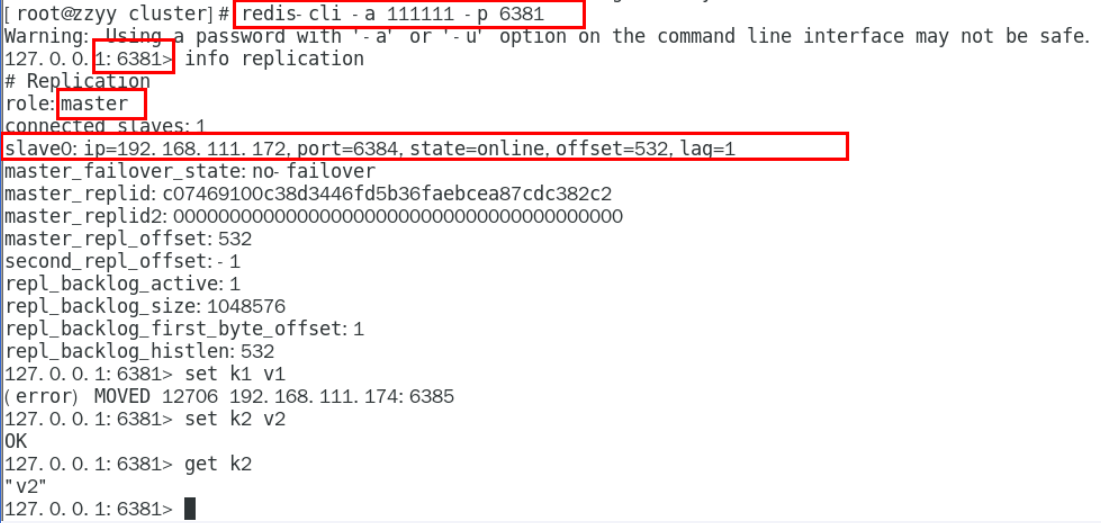
info replication

cluster nodes


三主三从 redis 集群读写

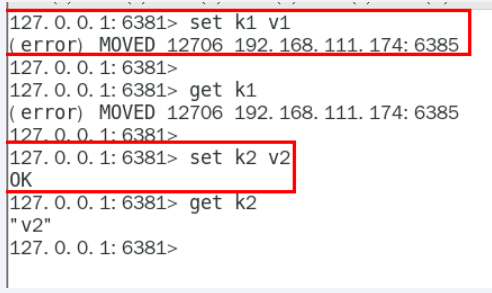

由于槽位的限制,不再是想怎么存就怎么存,需要路由到位

内部由于有 CRC16 和重定向算法 k1 被重定向到另一个槽位
连接集群需要加 c, 这样连接的是大redis
redis-cli -a password -p 6385 -c
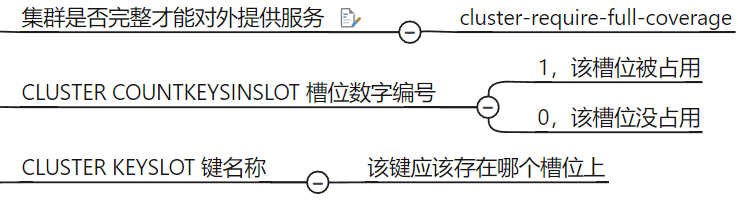
cluster keyslot 键
查看某个 key 的槽位值

主从容错切换迁移案例

master 挂后 slave 会自动上位,即使之前 master 重新回归,也会变成slave

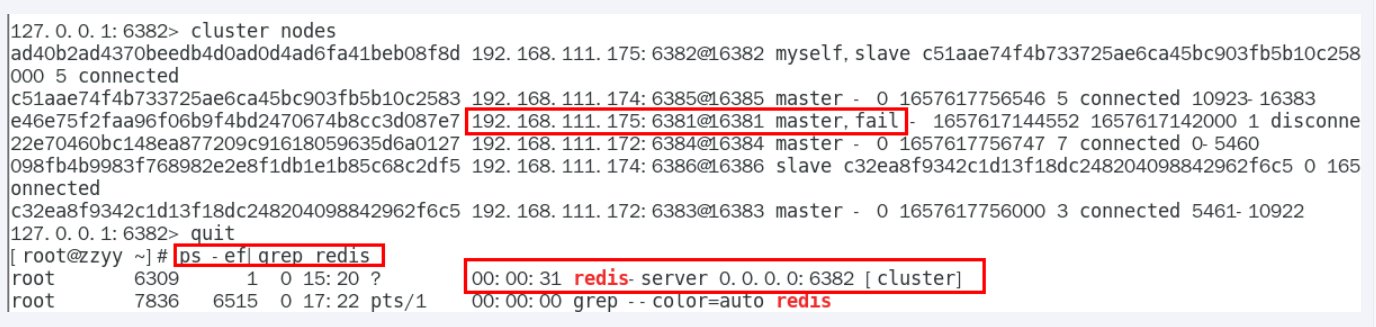
恢复后变成slave

手动故障转移 or 节点从属调整
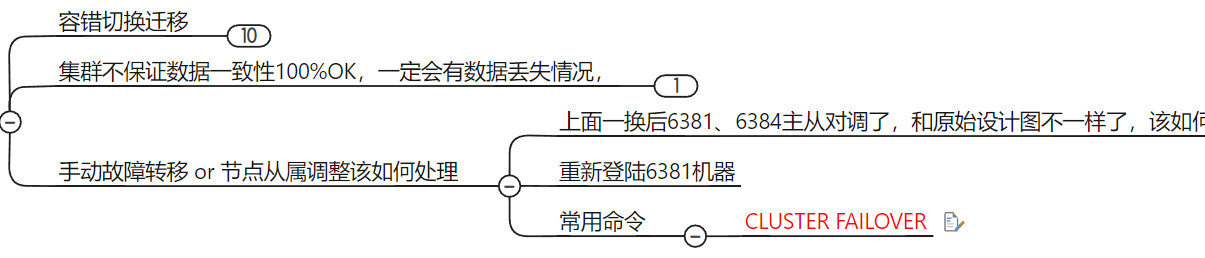
CLUSTER NODES

将之前的 master 恢复后还变成master
主从扩容案例
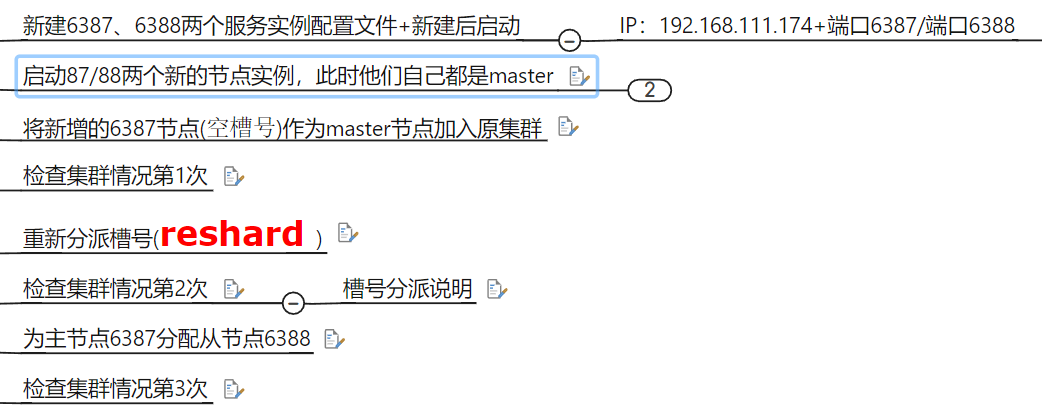
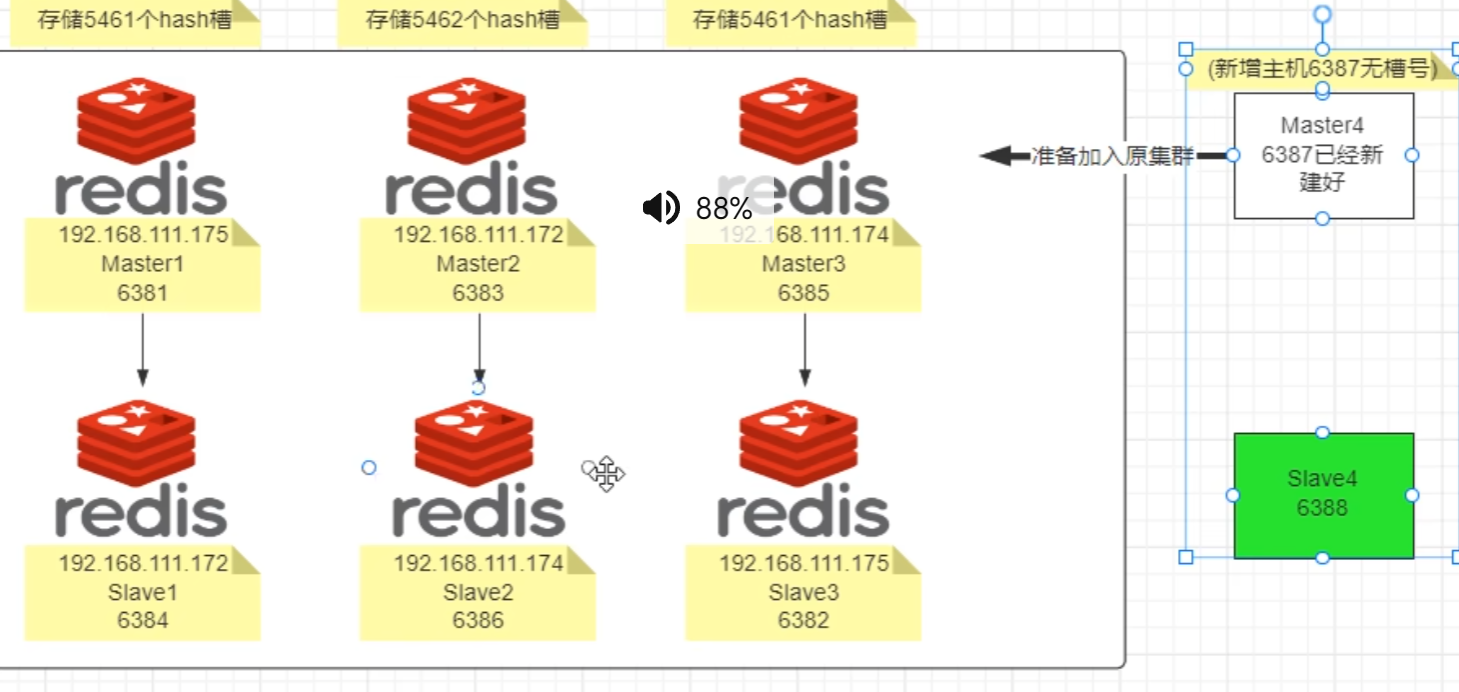
添加
redis-cli -a password --cluster add-node ip1:port1 ip:port
ip1:port1是新加的地址
ip:port是已有的地址
加入后不会被分配槽号

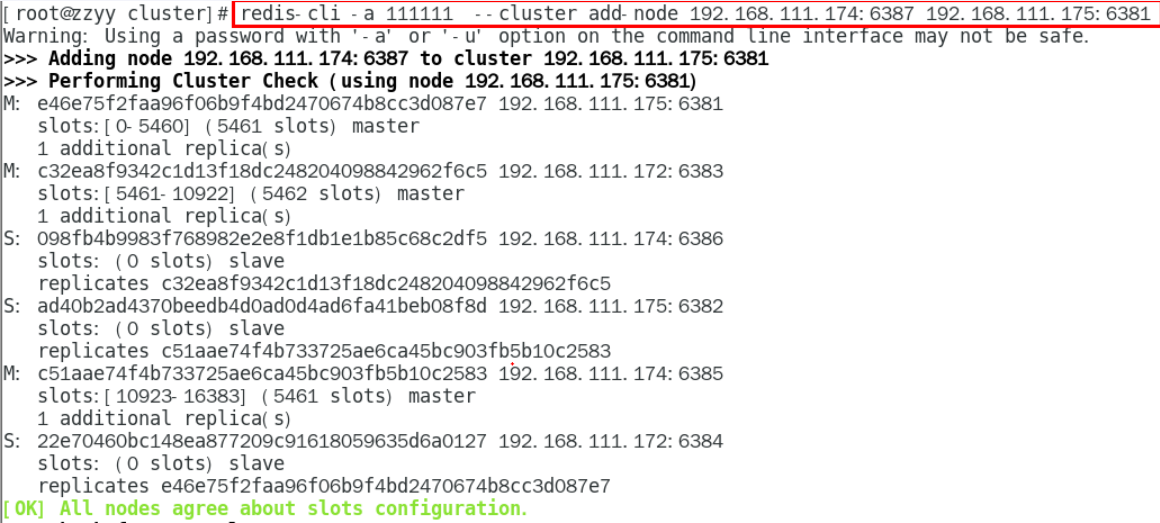
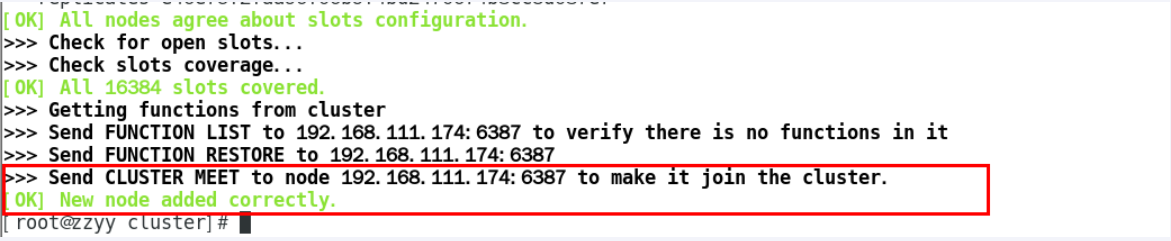
检查

加入后不会被分配槽号
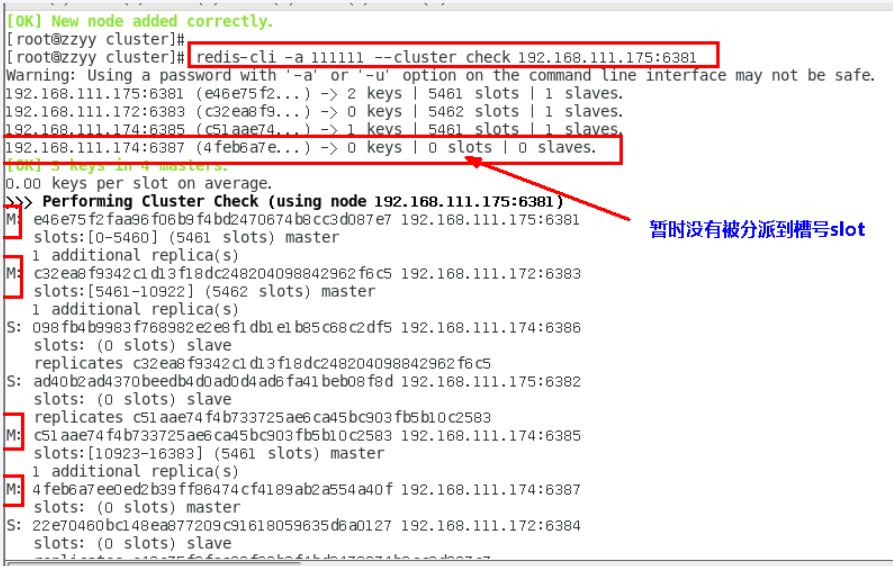
重新分配槽号 (
reshard)
redis-cli -a psw --cluster reshard ip:port

填 16384/4=4096

填新的 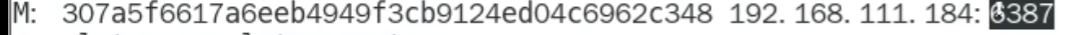

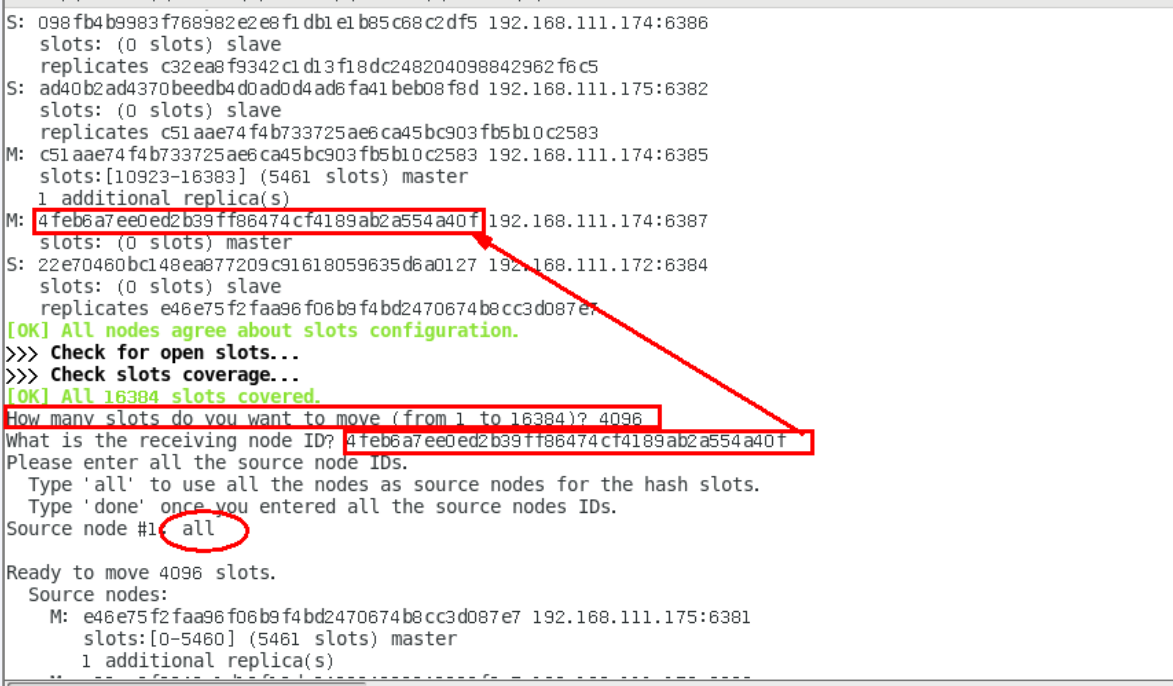
分配好了槽位,目前还没有挂slave
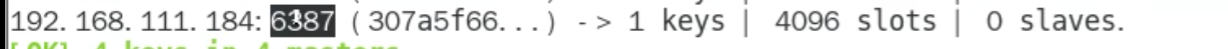



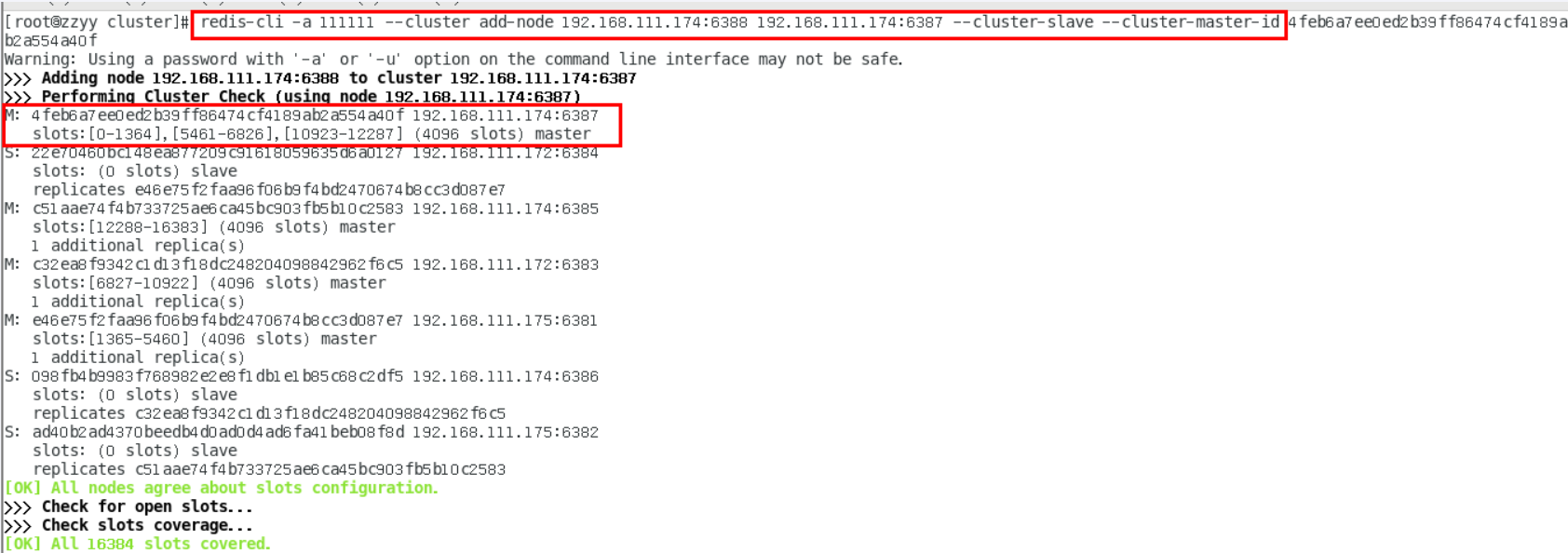

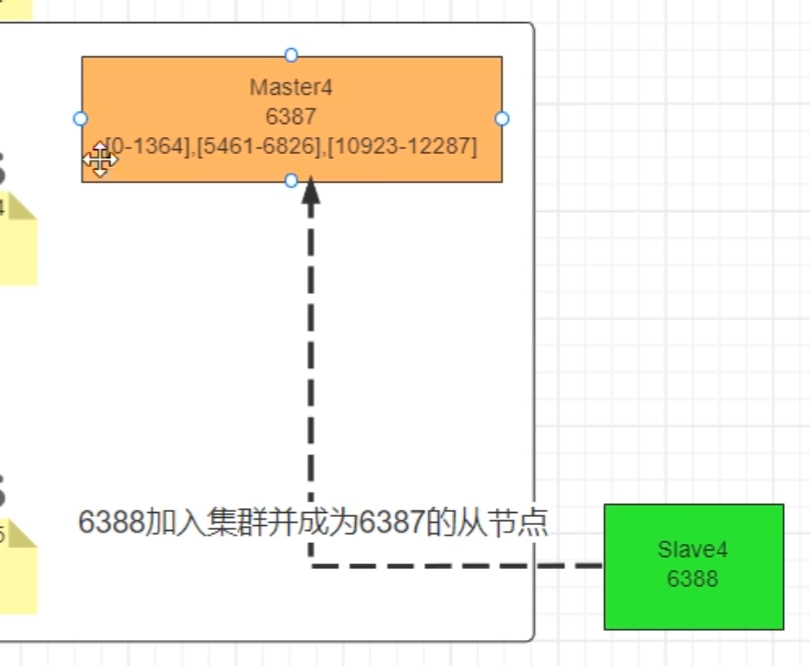
主从缩容案例
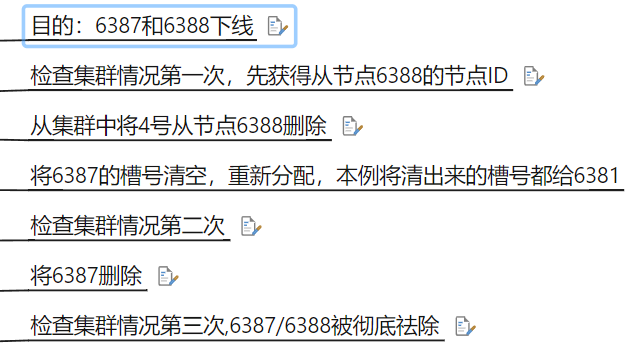
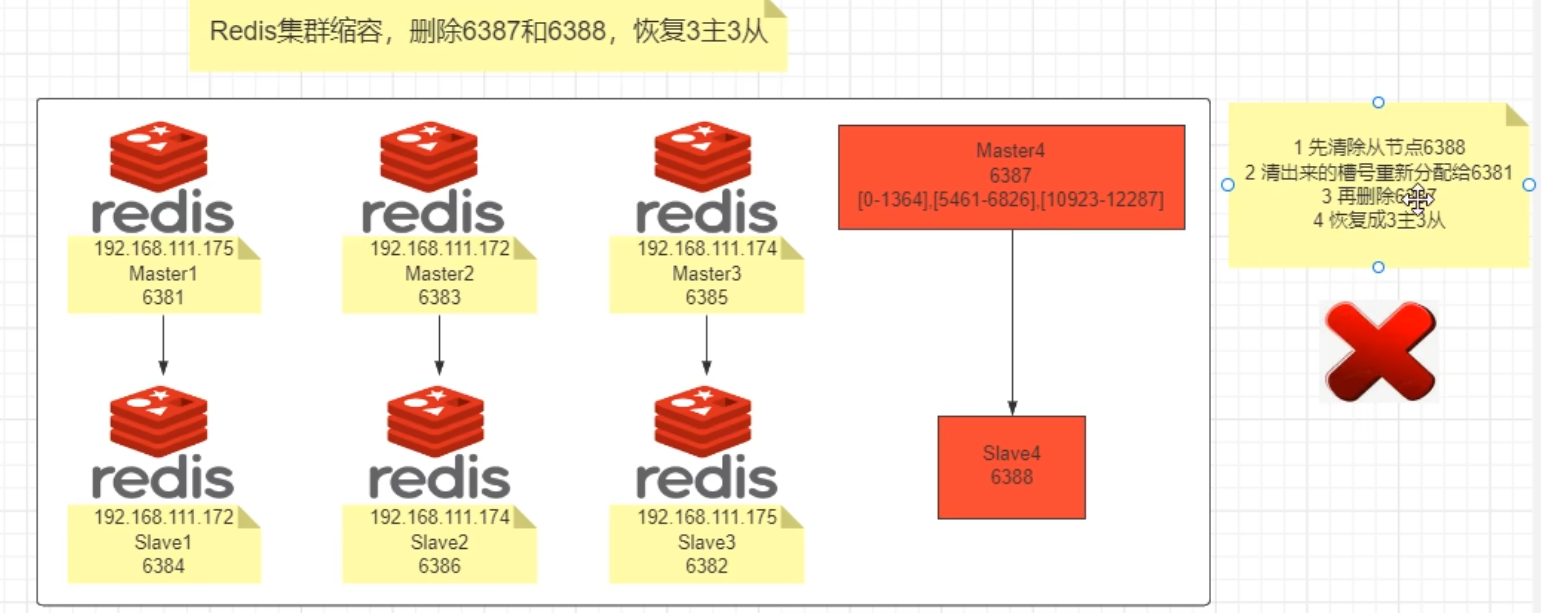
redis-cli -a psw --cluster del-node ip:port ID


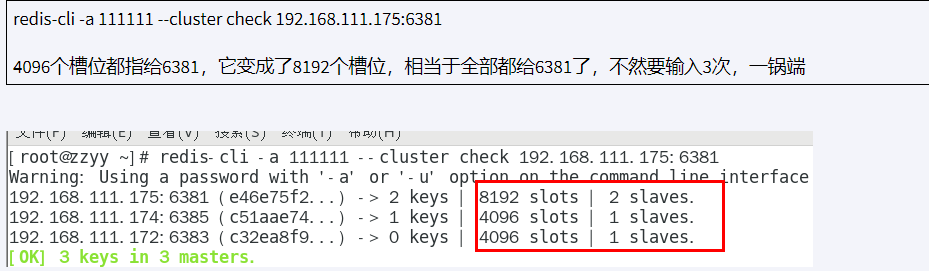
slave 被成功删除,接下来将 6387 的槽号清空,重新分配 (本例群不还给了 6381)
redis-cli -a psw --cluster reshard ip:6381
然后输入 4096
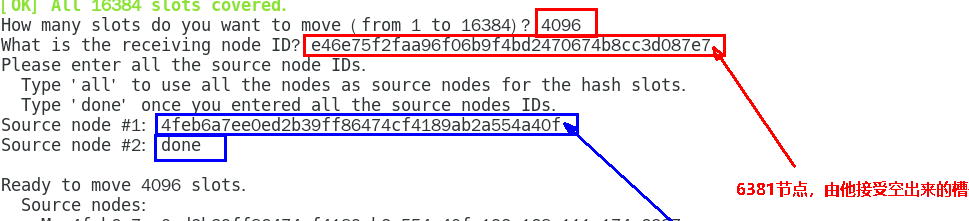

不需要两个 slave , 之后将 6387 删除
redis-cli -a psw --cluster del-node ip:port ID

集群常用操作命令和 CRC16 算法分析



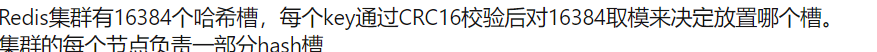
cluster keyslot key
cluster countkeysinslot 12707
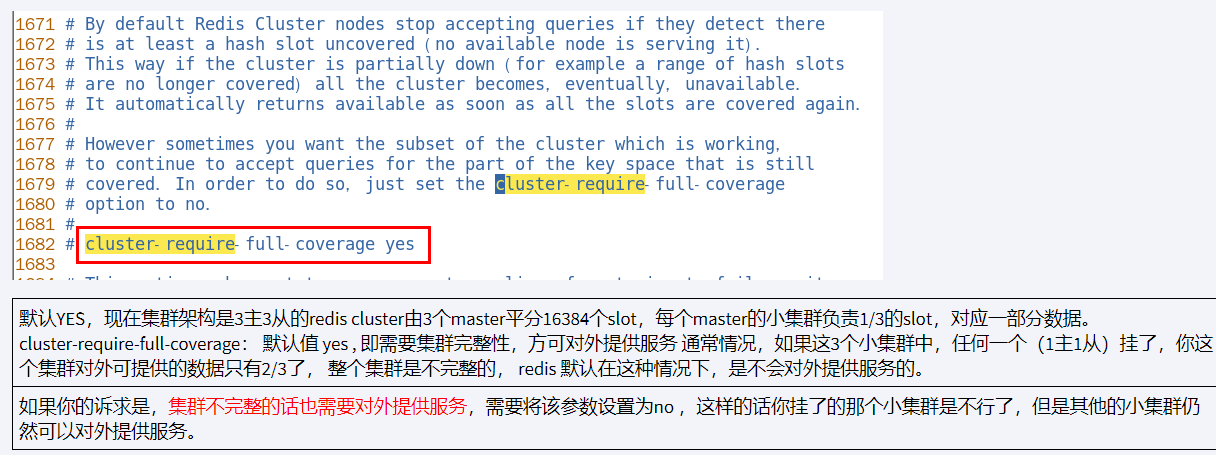
Spring 使用 Redis

RedisTemplate


title: yaml
```java
server.port=7777
spring.application.name=redis7_study
# ========================logging=====================
logging.level.root=info
logging.level.com.atguigu.redis7=info
logging.pattern.console=%d{yyyy-MM-dd HH:mm:ss.SSS} [%thread] %-5level %logger- %msg%n
logging.file.name=D:/Users/XCJY/Desktop/qianduan
logging.pattern.file=%d{yyyy-MM-dd HH:mm:ss.SSS} [%thread] %-5level %logger- %msg%n
# ========================swagger=====================
spring.swagger2.enabled=true
#在springboot2.6.X结合swagger2.9.X会提示documentationPluginsBootstrapper空指针异常,
#原因是在springboot2.6.X中将SpringMVC默认路径匹配策略从AntPathMatcher更改为PathPatternParser,
# 导致出错,解决办法是matching-strategy切换回之前ant_path_matcher
spring.mvc.pathmatch.matching-strategy=ant_path_matcher
# ========================redis单机=====================
spring.redis.database=0
# 修改为自己真实IP
spring.redis.host=192.168.111.185
spring.redis.port=6379
spring.redis.auth=111111
spring.redis.lettuce.pool.max-active=8
spring.redis.lettuce.pool.max-wait=-1ms
spring.redis.lettuce.pool.max-idle=8
spring.redis.lettuce.pool.min-idle=0
lettuceConnectionFactory 适合高并发
title: RedisConfig
```java
@Configuration
public class RedisConfig
{
/**
* redis序列化的工具配置类,下面这个请一定开启配置
* 127.0.0.1:6379> keys *
* 1) "ord:102" 序列化过
* 2) "\xac\xed\x00\x05t\x00\aord:102" 野生,没有序列化过
* this.redisTemplate.opsForValue(); //提供了操作string类型的所有方法
* this.redisTemplate.opsForList(); // 提供了操作list类型的所有方法
* this.redisTemplate.opsForSet(); //提供了操作set的所有方法
* this.redisTemplate.opsForHash(); //提供了操作hash表的所有方法
* this.redisTemplate.opsForZSet(); //提供了操作zset的所有方法
* @param lettuceConnectionFactory
* @return
*/
@Bean
public RedisTemplate<String, Object> redisTemplate(LettuceConnectionFactory lettuceConnectionFactory)
{
//开始创建redis模板对象...
RedisTemplate<String,Object> redisTemplate = new RedisTemplate<>();
//设置redis的连接工厂对象
redisTemplate.setConnectionFactory(lettuceConnectionFactory);
//设置key序列化方式string
redisTemplate.setKeySerializer(new StringRedisSerializer());
//设置value的序列化方式json,使用GenericJackson2JsonRedisSerializer替换默认序列化
redisTemplate.setValueSerializer(new GenericJackson2JsonRedisSerializer());
//设置哈希序列化方式
redisTemplate.setHashKeySerializer(new StringRedisSerializer());
redisTemplate.setHashValueSerializer(new GenericJackson2JsonRedisSerializer());
//RedisTemplate 的所有属性设置完成后,进行一些初始化操作
redisTemplate.afterPropertiesSet();
return redisTemplate;
}
}

title: SwaggerConfig
```java
@Configuration
@EnableSwagger2
public class SwaggerConfig
{
@Value("${spring.swagger2.enabled}")
private Boolean enabled;
@Bean
public Docket createRestApi() {
return new Docket(DocumentationType.SWAGGER_2)
.apiInfo(apiInfo())
.enable(enabled)
.select()
.apis(RequestHandlerSelectors.basePackage("com.atguigu.redis7")) //你自己的package
.paths(PathSelectors.any())
.build();
}
public ApiInfo apiInfo() {
return new ApiInfoBuilder()
.title("springboot利用swagger2构建api接口文档 "+"\t"+ DateTimeFormatter.ofPattern("yyyy-MM-dd").format(LocalDateTime.now()))
.description("springboot+redis整合,有问题给管理员阳哥邮件:zzyybs@126.com")
.version("1.0")
.termsOfServiceUrl("https://www.atguigu.com/")
.build();
}
}
RedisTemplate 操作类
Spring 提供的 Redis 数据结构的操作类
ValueOperations类,提供Redis String API操作ListOperations类,提供Redis List API操作SetOperations类,提供Redis Set API操作ZSetOperations类,提供Redis ZSet(Sorted Set) API操作GeoOperations类,提供Redis Geo API操作
序列化问题
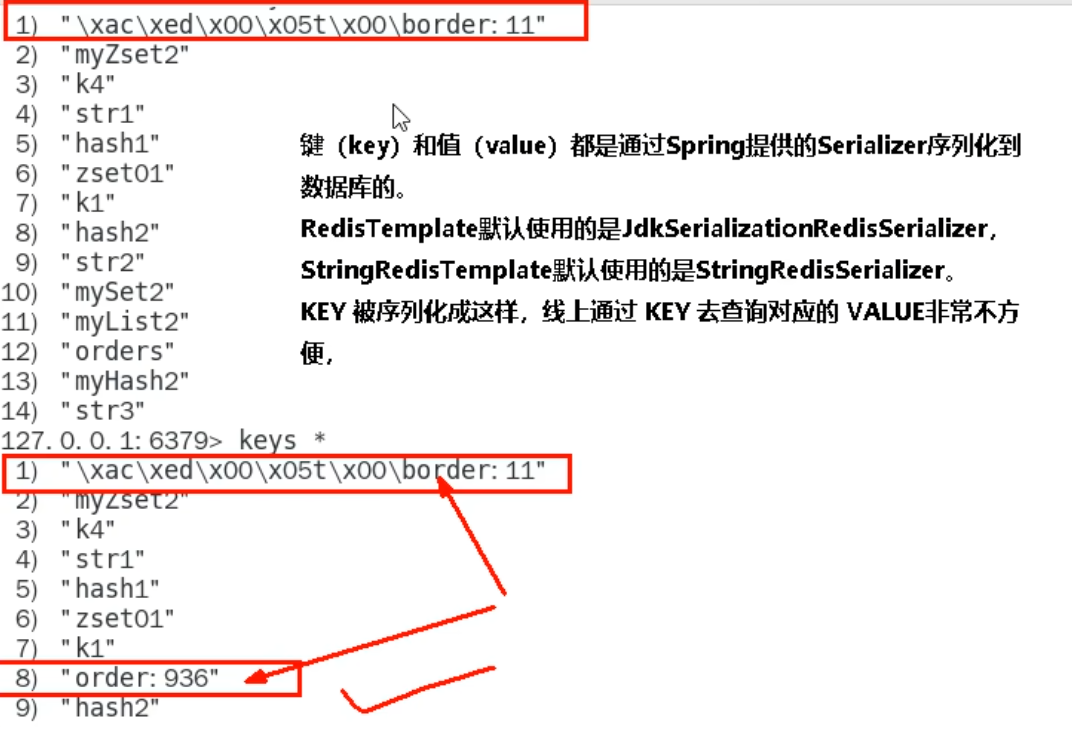
//ThreadLocalRandom.current(): 获取与当前线程绑定的线程本地随机数生成器
//.nextInt(1000): 生成一个0到999之间的随机整数
//+1: 将生成的随机整数加1,使范围变为1到1000
int keyId= ThreadLocalRandom.current().nextInt(1000)+1;
String serialNO= UUID.randomUUID().toString();
将 redisTemplate 默认使用的``
想让 linux 客户端查看中文 --raw
否则是乱码

原因
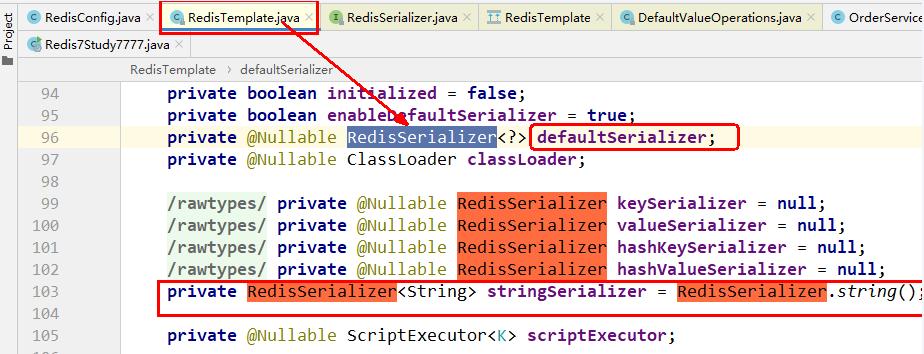
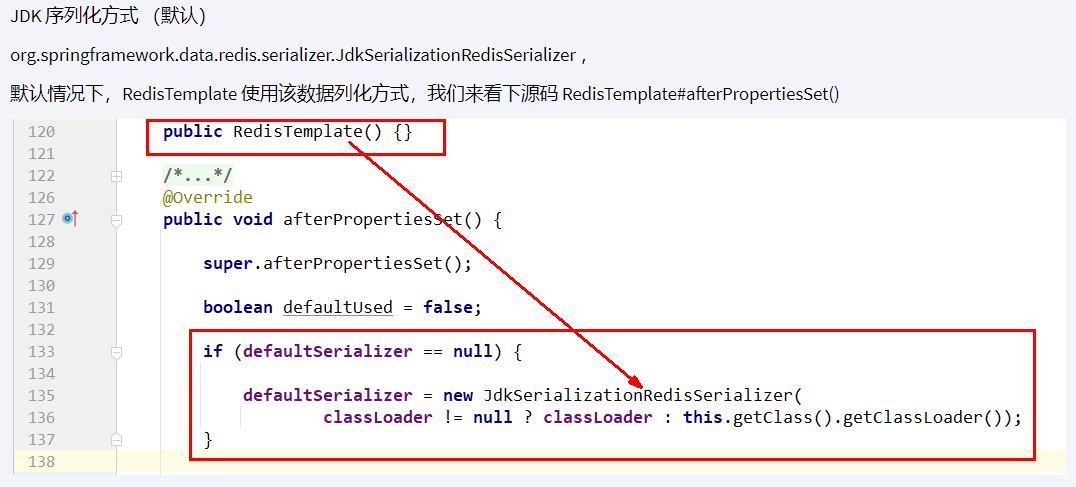
默认的是 JDK 序列化方式,会导致乱码,通过手动指定替换掉默认的

连接集群
title: 连接集群配置
```java
spring.redis.password=111111
# 获取失败 最大重定向次数
spring.redis.cluster.max-redirects=3
spring.redis.lettuce.pool.max-active=8
spring.redis.lettuce.pool.max-wait=-1ms
spring.redis.lettuce.pool.max-idle=8
spring.redis.lettuce.pool.min-idle=0
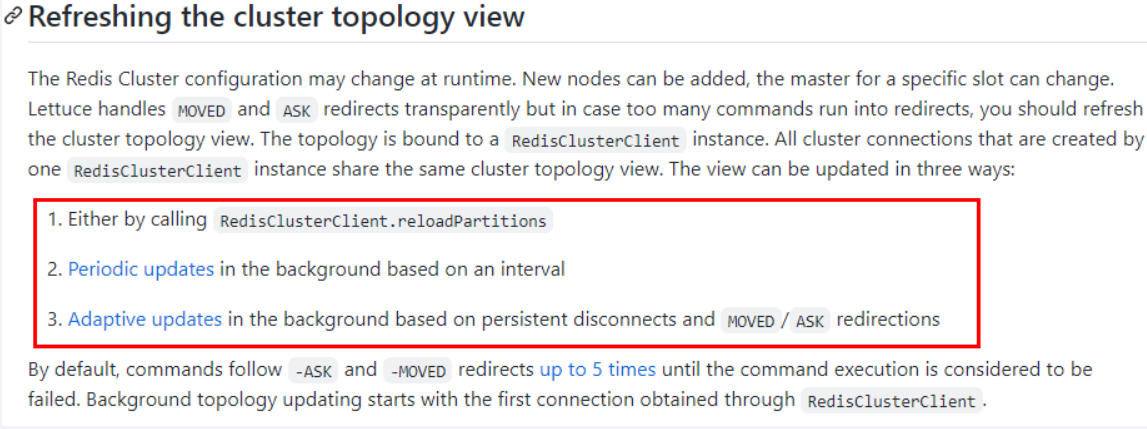
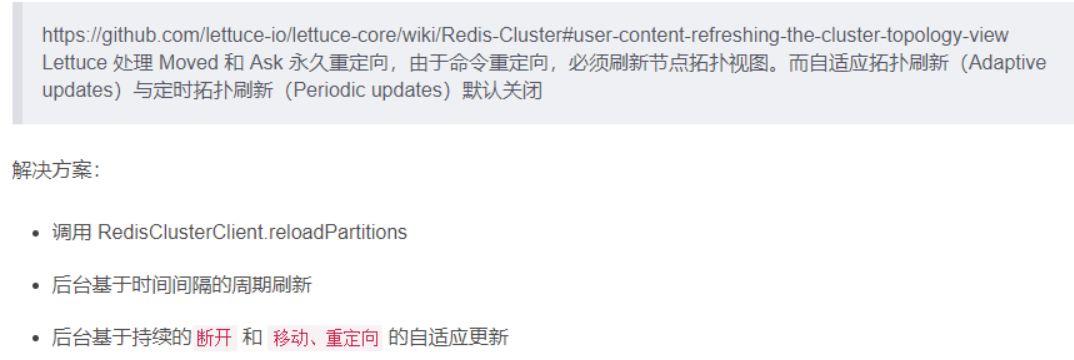
#支持集群拓扑动态感应刷新,自适应拓扑刷新是否使用所有可用的更新,默认false关闭,不添加master挂后spring不知道
spring.redis.lettuce.cluster.refresh.adaptive=true
#定时刷新
spring.redis.lettuce.cluster.refresh.period=2000
spring.redis.cluster.nodes=192.168.111.175:6381,192.168.111.175:6382,192.168.111.172:6383,192.168.111.172:6384,192.168.111.174:6385,192.168.111.174:6386


解决方案

#支持集群拓扑动态感应刷新,自适应拓扑刷新是否使用所有可用的更新,默认false关闭,不添加master挂后spring不知道
spring.redis.lettuce.cluster.refresh.adaptive=true
#定时刷新
spring.redis.lettuce.cluster.refresh.period=2000
资料
- 起步思维: 官网
- 排除故障思维 : 日志
![[assets/Redis入门/Redis脑图(基础篇+高级篇).html]]